今天晚上,阿祖在电脑前干了一件又蠢又典型的事。领导让阿祖帮忙翻一份两年前的合作协议原文,说里面有个条款要复盘。我打开公司网盘,一路从“客户资料—已签约—归档—2024”点下去,迎面就是一整个墓地式的文件名:“最终版_v3.pdf”“最终版_终极版.pdf”“老板改过.pdf”。我一边下载一边在心里骂人:两年过去了,谁还能记得哪一份才是真正执行的那一版?更魔幻的是,就算我把这份“正确版本”的合同丢进 IPFS,在链上挂了一个哈希,区块浏览器也只会冷冰冰给我一串十六进制字符串。链看不懂条款,AI 看不懂语义,除了“证明它存在过”以外,谁都不真正理解这份文件。这一刻我突然意识到:在今天的大部分系统眼里,“文件”本质上都是冷尸体——被装进网盘、打包进哈希、扔到某个节点角落里,只有在我们跪着搜索的时候才被从坟里刨出来用一次。
问题是,我们现在天天挂在嘴边的是“AI 时代”。如果数据还是这样被当成尸体对待,那所谓的 AI 上链、Agent 经济,说难听点,很多时候只是给冷尸体换一个更精致的棺材。传统存储的底层假设特别简单粗暴:文件就是一堆字节。网盘的工作,是帮你把这堆字节放远一点、多备几份;公链更省事,直接把文件丢给 IPFS,只在链上留个哈希,再配个网关。Web2 年代还能这么凑合,是因为真正理解文件内容的,是人——合同要靠律师看,审计报告要靠会计看,运营报表要靠运营导出到 Excel 再拉透视表。但在 AI 时代,这个逻辑已经倒过来了:真正需要“读懂文件”的,不再只是人,而是一整群 7×24 小时在线的智能体。
想象一下,你的 AI 助理帮你做几件很正常的事:自动从历史合同里抽出所有“解约条款”做风险列表;帮你翻一整套房产交易文件,找出税务与合规风险;记住你过去一年所有发票、机票、酒店订单,在报税季自动整理成税表。如果这些东西都躺在“冷文件”里,AI 每次要用它们,都得重新下载、重新解析、重新理解一遍。换一个产品,记忆又全废掉重来。数据在这种模式下,从头到尾只是“一次性的输入”,而不是“长期可复用的记忆”。这就是多数所谓“AI 应用”的死穴:模型看上去很聪明,但它根本没有可以长期依赖的语义记忆层。
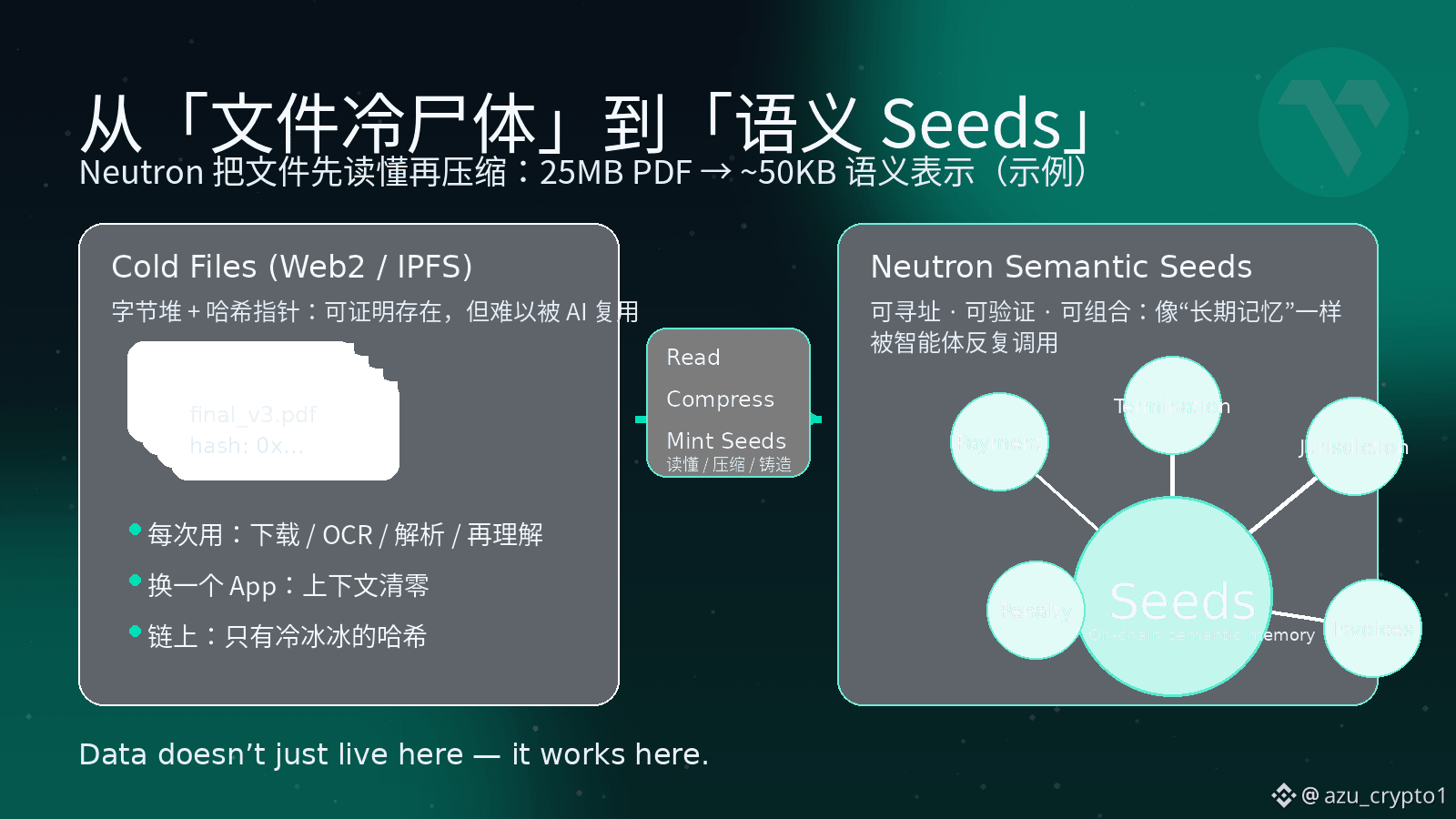
Vanar 给出的答案叫 Neutron。它干脆不把自己定位成什么“又一个存储方案”,而是非常直接地说:这是一个 Semantic Memory Layer ——语义记忆层。用人话说,Neutron 做两件事。第一步,是先“读懂”文件,再压缩。它不是简单地把 PDF 打个 zip,而是先用语义和启发式方法把原始文件切成有意义的片段,再重构成新的表示;压的是“信息冗余”和“表达方式”,不是内容本身。你给它一份 25MB 的 PDF,它能在理解内容之后,把核心语义压成大约 50KB 级别的表示,但你要的信息、上下文和结构还在。第二步,是把这种理解后的结果铸造成一颗颗 Seeds——可以被 AI 读懂、被合约引用的“知识种子”。Neutron 不再把文件当作一整坨 blob,而是拆成很多颗 Seeds,每一颗都是一个独立的、可寻址、可验证的语义单元,而且是直接上链的,不是“链下存文件 + 链上放指针”那种半吊子方案。
在 Neutron 的世界里,文件不再只是“一个链接”“一个哈希”,而是一整片可以被 AI 播种、被应用层反复收割的语义土地。你可以把 Seeds 想象成“文件的灵魂”:肉身在上传和迁移中早就变化无数次,但这些 Seeds 上刻着的,是这份文件真正想表达的东西,而且可以被不同的智能体共享使用。原来 25MB 的大文件,进来之后被压成几十 KB 的 Seeds 集合,这些 Seeds 全部上链,变成一个可以被索引、被证明、被组合的长期记忆。

这时候,很多原本很痛的场景就会发生明显的相变。比如前面提到的那份 25MB 的法律合同,进了 Neutron 之后,会被拆成多颗 Seeds:有一颗对应所有“违约责任”的条款,有一颗对应“付款条件”,还有一颗承载“适用法律与争议解决机制”。当你在 Vanar 生态里的某个智能体想问:“帮我找出所有在某个司法辖区、带仲裁条款、违约罚金超过 X 的合约,并估算一旦违约我要付多少钱。”它根本不需要再去把原始 PDF 下载回来暴力扫一遍,而是可以直接在链上的 Seeds 上跑查询。对 AI 来说,链不再是“记账本”,而是真正变成一个“可搜索的法律知识库”。
再比如发票和报表。你把一年所有发票、机票、酒店订单都丢给 Neutron,它会把这些发票压成一串按语义分组的 Seeds:金额、税率、品类、供应商都被结构化了。当报税季来临,你只需要对你的 AI 说一句:“帮我算今年可以抵扣多少税,按税局模板导出来。”智能体不再从 jpg 和 pdf 做 OCR 起步,而是直接站在 Seeds 之上做运算。原本那堆被你散落在邮箱和网盘角落里的杂乱票据,第一次变成了“会自己工作的资产”。
更有意思的是,Seeds 不是某个 App 的私有格式,而是整个 Vanar 栈的公共语言。你在 myNeutron 里生成的一颗知识 Seed,未来可以被其他 Vanar 生态应用,甚至被 Kayon 这样的链上推理引擎直接读取和调用;记忆不再属于某个应用,而是属于你,也属于这条链。Vanar 那句“Reimagine data. Rewrite the stack.”就体现在这里:数据不再只是被动地“活着”,而是真正开始“工作”。在 Neutron 之前,链上的绝大多数数据都是死账,一笔笔交易,一个个哈希;在 Neutron 之后,被压进 Seeds 的文件,会持续为 AI 和合约提供上下文,而不是静静躺在冷存里吃灰。
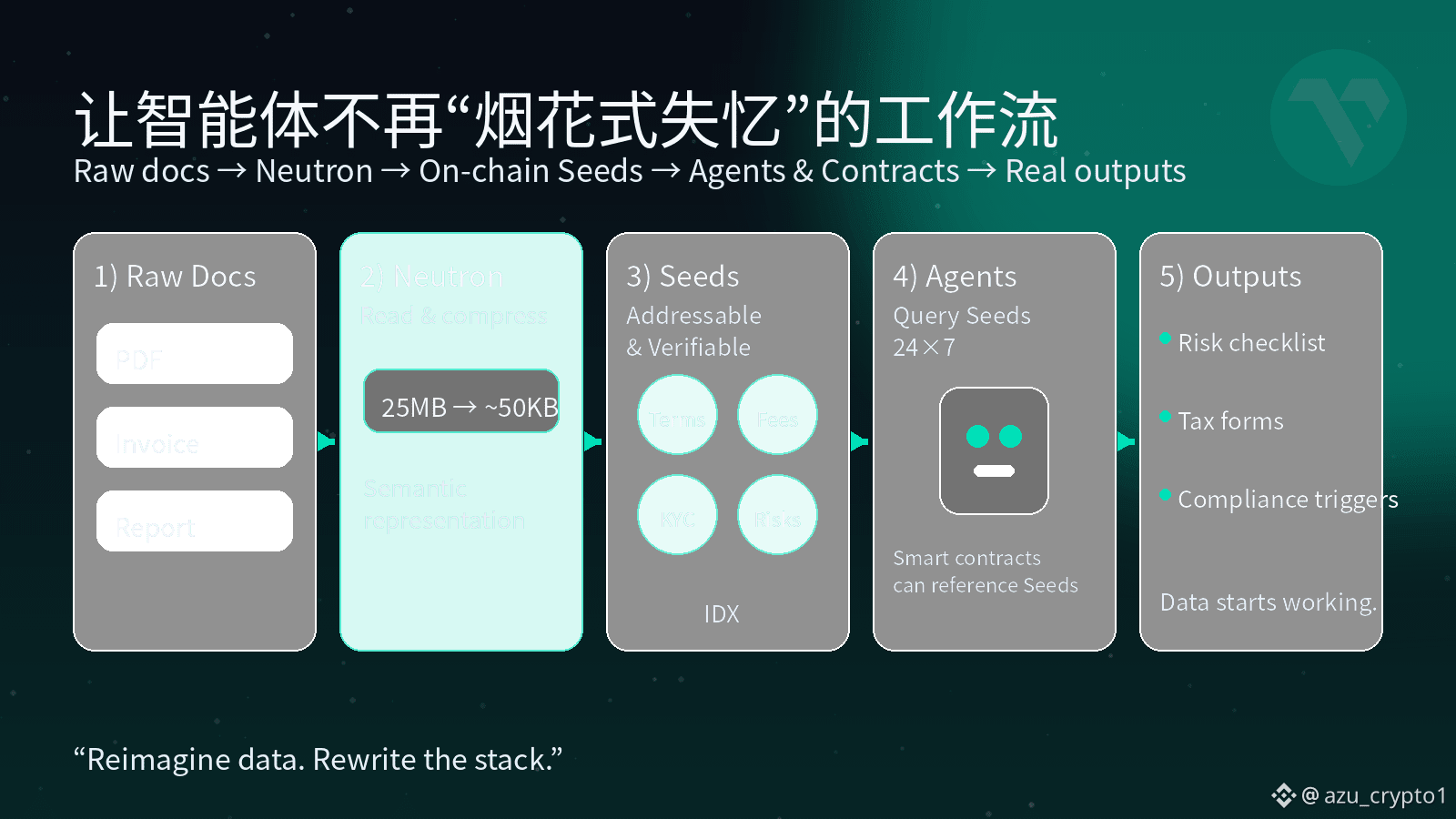
从架构上看,Vanar 把 Neutron 放在一个非常微妙但关键的位置:底层是负责执行与结算的 L1,上层有专门做推理的 Kayon,可以直接读取 Seeds 做 on-chain reasoning,中间这一层 Neutron,则专门负责把原始世界的文件,变成 AI 能理解、合约能调用的“语义记忆”。大部分人在聊“AI 公链”的时候,还是在卷 TPS、卷手续费、卷“带不带原生大模型”,但真正跑产品的团队慢慢都会发现:如果你解决不了“记忆”和“数据语义化”的问题,所有 Agent、所有自动化,最后都会退化成一次性的烟花——今天陪你聊天,明天完全忘了你是谁,下周你换一个产品,之前的上下文当场作废。
Neutron 做的事,听起来一点也不性感:它不搞“十倍 TPS”、不喊“全球最大生态”,只是把“文件是冷尸体”这件事默默改写成“文件是会思考、可编程的 Seeds”。在阿祖看来,这颗看上去不起眼的“压缩螺丝钉”,很可能会决定一件大事:AI 时代的链,究竟是继续当一个高级版记账本,还是第一次真正拥有属于自己的长期记忆。等到 2026 年,真有人开始把 Agent 扔到链上帮自己管资产、跑工作流的时候,你会发现:算力是可以租的,模型是可以换的,甚至 L1 都是可以迁移的,但那一整片被压进 Seeds 的长期记忆,是任何一个智能体系统最不愿意割舍的东西。
所以当市场还在盯着谁 TPS 更高、谁又整了个新模型、谁今天在社交媒体上喊得更响时,我反而更愿意花时间盯着这些埋在中间层的小组件。因为历史一再证明:真正改变游戏规则的,往往不是台上拿话筒的人,而是那些在台下把螺丝一颗一颗拧紧的工程师。而在 Vanar 的故事里,Neutron 就是那颗把“25MB 文件压成 50KB 会思考的 Seeds”的小螺丝——它不抢风头,但它决定了整套 AI 栈能不能长期站得住。
