
If you’ve been watching VANRY lately, you know the vibe. It’s not a hype tape. It’s a grind. As of today, VANRY is trading around $0.00635 with roughly $2.8M in 24h volume and about a $14.3M market cap on ~2.256B circulating supply. That’s small enough that one real enterprise pipeline can matter, but also small enough that the market can ignore it for months if nothing shows up in usage.
So why are people even talking about enterprises “choosing” Vanar in the first place? Because the enterprise AI pitch has quietly changed. A year ago it was “AI agents will do everything.” Now it’s “AI agents will do everything, until they touch messy data.” Enterprises don’t lose sleep over model demos. They lose sleep over data integrity, permissions, audit trails, and the fact that half their workflows still live in PDFs, emails, and screenshots.
Here’s the key: AI is only as good as the data you can trust and retrieve at the moment you need it. In trading terms, the model is the strategy, but the data pipeline is your execution venue. If your fills are fake or delayed, your strategy doesn’t matter.
Vanar’s bet is basically that data should stop being “dead weight” and become something a system can verify, reference, and reason over without turning into a compliance nightmare. Their Neutron concept is built around “Seeds,” which are structured knowledge units that can be stored offchain for speed, with an option to anchor metadata and verification onchain when you need provenance. In the docs, they’re explicit about a dual storage architecture: offchain by default for performance, onchain for immutable metadata, cryptographic verification, audit logs, and access control. That’s the enterprise-friendly angle: you don’t shove raw sensitive files onto a public chain, but you can still get verifiability and history when it matters.
And they go harder on privacy than most “let’s put data onchain” narratives. The Neutron core concepts describe client-side encryption, encrypted hashes, encrypted pointers, embeddings stored onchain up to a stated size, plus owner permissions and document history, with the claim that only the owner can decrypt what’s stored. Whether every implementation detail holds up in production is the real test, but the architecture is aimed at the exact tension enterprises live in: keep the data private, but make the outcome provable.
Now here’s the thing traders often miss. Enterprises don’t adopt tech because it’s cool. They adopt it when it reduces operational risk. If your internal AI assistant can’t prove where an answer came from, or can’t show an audit trail, it becomes a liability. A lot of enterprise AI “wins” end up being narrow because the data layer is brittle. So when Vanar markets an integrated stack where Neutron is the memory layer and Kayon is the reasoning interface, the interesting part is not the chatbot vibe. It’s the implied workflow: ask a question, retrieve the right internal context, and optionally anchor integrity and timestamps in a way that’s hard to dispute later.
What about the “enterprises are choosing it” claim, specifically? The cleanest evidence is partnership announcements with real-world businesses that have actual compliance and operational constraints. For example, Vanar announced a partnership with Worldpay around Web3 payment solutions, and the coverage notes Worldpay’s scale and global footprint. Another example is the RWA angle through a strategic partnership with Nexera focused on real-world asset integration and compliance infrastructure. Are these guarantees of adoption? No. But they’re the type of counterparties that don’t waste time integrating with systems that can’t at least speak the language of auditability and control.
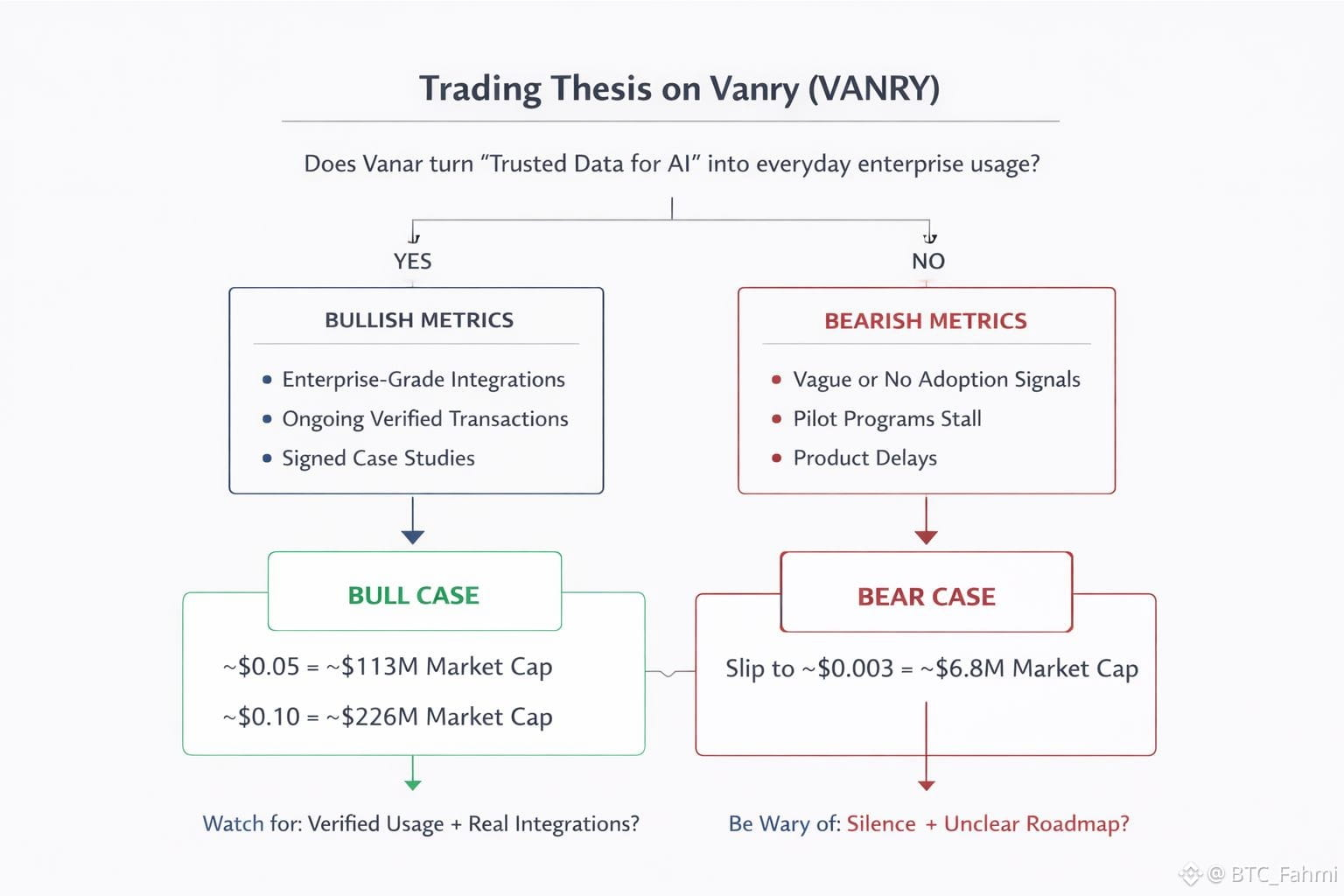
So what’s the trade, not the story? At $14M-ish market cap, you’re not paying for a proven enterprise revenue machine. You’re paying for an option on whether this “data you can verify” framing turns into usage. The bull case is pretty straightforward math plus execution. If Vanar converts even a small set of enterprise or fintech workflows into consistent transaction demand, a re-rate from $14M to, say, $100M market cap is not crazy in percentage terms. With ~2.256B circulating supply, $0.05 is about a $113M market cap, and $0.10 is about $226M. That’s not a prediction, it’s just what the numbers mean. The question is what would justify it: recurring activity tied to data workflows, not one-off announcements.
The bear case is also simple. Enterprise pilots stall all the time. “Partnership” can mean anything from a press cycle to a real integration with volume. If Neutron and the broader stack don’t translate into developers shipping, or if the “Seeds” idea ends up being more marketing than tooling, you can easily see VANRY drift with no bid. At $0.003, you’re looking at roughly a $6.8M market cap. And if liquidity stays thin, price can move down faster than fundamentals improve.
What would change my mind either way? On the bullish side, I’d want to see proof of repeatable usage that looks like an enterprise pattern: steady onchain activity tied to data verification, signed customer case studies, and integrations that imply ongoing workflows, not just a demo. On the bearish side, the red flags are silence and vagueness: no measurable adoption signals, no clear developer traction, and a roadmap that keeps pushing the “real” product out another quarter.
If you’re looking at this as a trader, treat it like a thesis that lives or dies on one thing: do they turn “AI needs trusted data” into a product people actually run every day. Track the market basics, price, volume, supply, because it tells you whether the market is waking up. Then track the real signal: enterprise-grade integrations that produce recurring activity, and the kind of auditability and permissioning features enterprises demand. If those metrics start rising while the token still trades like it’s forgotten, that’s when this gets interesting.
