
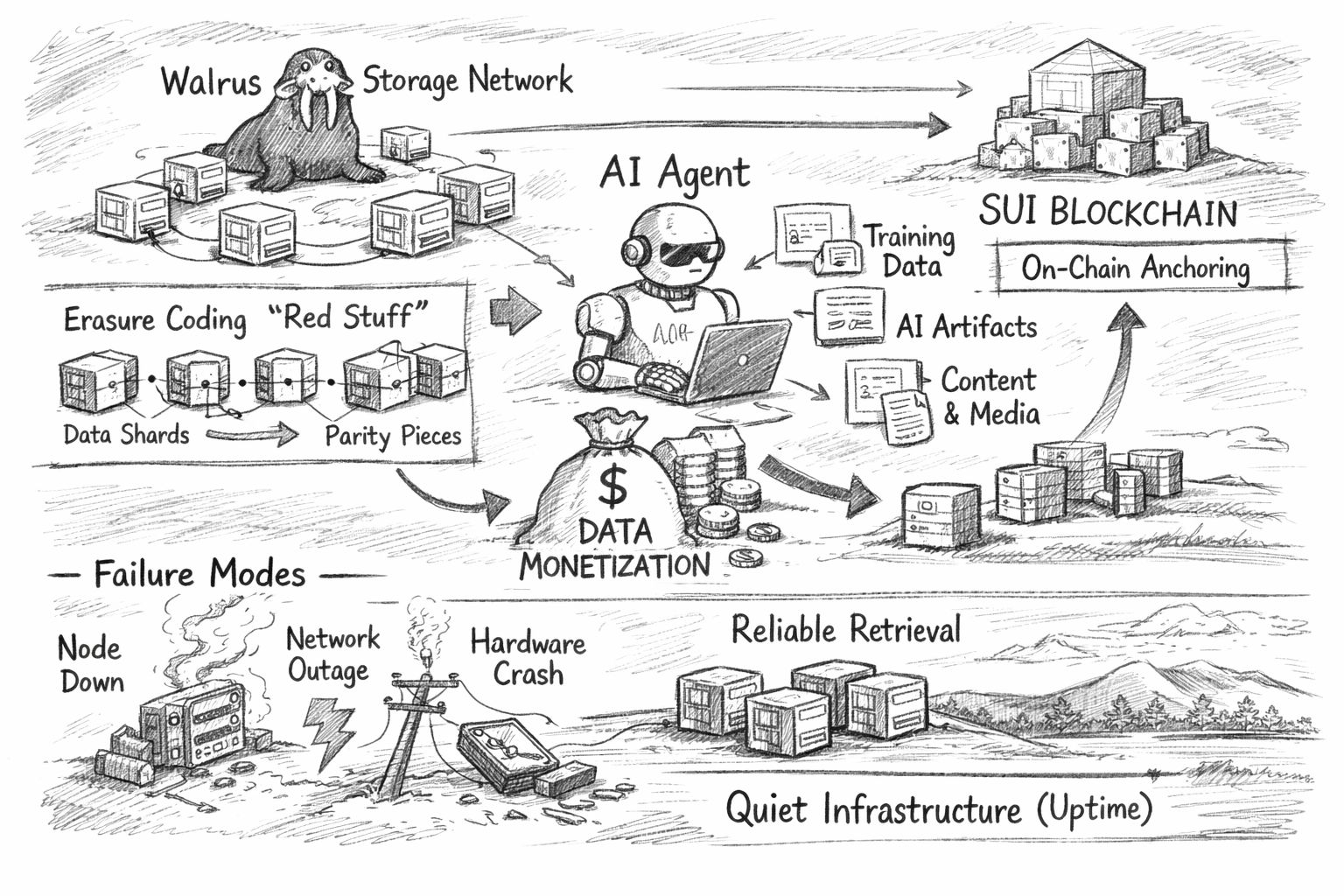
@Walrus 🦭/acc Os sistemas de criptografia tendem a celebrar o que podem contar. TPS, endereços ativos diários, taxas e novos contratos podem te dizer algo, mas também podem ser enganosos. É fácil confundir “muita coisa está acontecendo” com “um progresso real está sendo feito.” O armazenamento conquista confiança em um cronograma diferente. Um sistema de computação pode parecer ocupado por semanas e ainda falhar na primeira vez que um produto real depende dele sob pressão. Um sistema de armazenamento se torna “real” apenas quando as aplicações dependem dele dia após dia, quando a recuperação continua funcionando nas condições bagunçadas que as equipes tentam não pensar, e quando a história operacional é chata o suficiente para que as pessoas parem de falar sobre isso. Esse é o contexto para a abordagem do Walrus. O Walrus é basicamente uma rede de armazenamento descentralizada para grandes “blobs” de dados, projetada para tornar a recuperação confiável. Ele mira aplicativos que são pesados em conteúdo e dados, onde os arquivos são grandes, chegam constantemente ou importam demais para arriscar. A mensagem é clara: o armazenamento não é um complemento—é fundamental, porque a desvantagem de estragá-lo é muito maior do que as pessoas esperam. O Walrus também se enquadra como uma fundação para “mercados de dados” em uma economia moldada por IA, onde dados e os artefatos derivados deles podem ser controlados, acessados e pagos de uma maneira mais nativa. Essa estrutura é explícita em seus materiais públicos, que enfatizam os dados como um ativo e destacam casos de uso de agentes de IA ao lado de cargas de trabalho de conteúdo e mídia mais familiares.
Vale a pena insistir em por que o armazenamento é uma promessa mais difícil do que a computação. Os problemas de computação são geralmente locais e solucionáveis: você reexecuta o trabalho, troca a máquina, e uma interrupção se transforma em um relatório e um patch. Os problemas de armazenamento parecem mais pesados porque dados perdidos podem desaparecer para sempre. Você pode simular atividade de computação enviando chamadas baratas, mas não pode simular anos de recuperação confiável. Uma equipe séria não se importa que uma rede de armazenamento possa aceitar uploads hoje se não estiver confiante de que esses uploads ainda serão recuperáveis no próximo trimestre, no próximo ano e depois que os operadores originais tiverem partido. É por isso que a confiança no armazenamento é conquistada lentamente e perdida instantaneamente. É também por isso que a adoção tende a chegar mais tarde do que as narrativas sugerem. Os custos de troca são altos, e o modo de falha é brutal: você não apenas quebra um aplicativo, você quebra sua memória.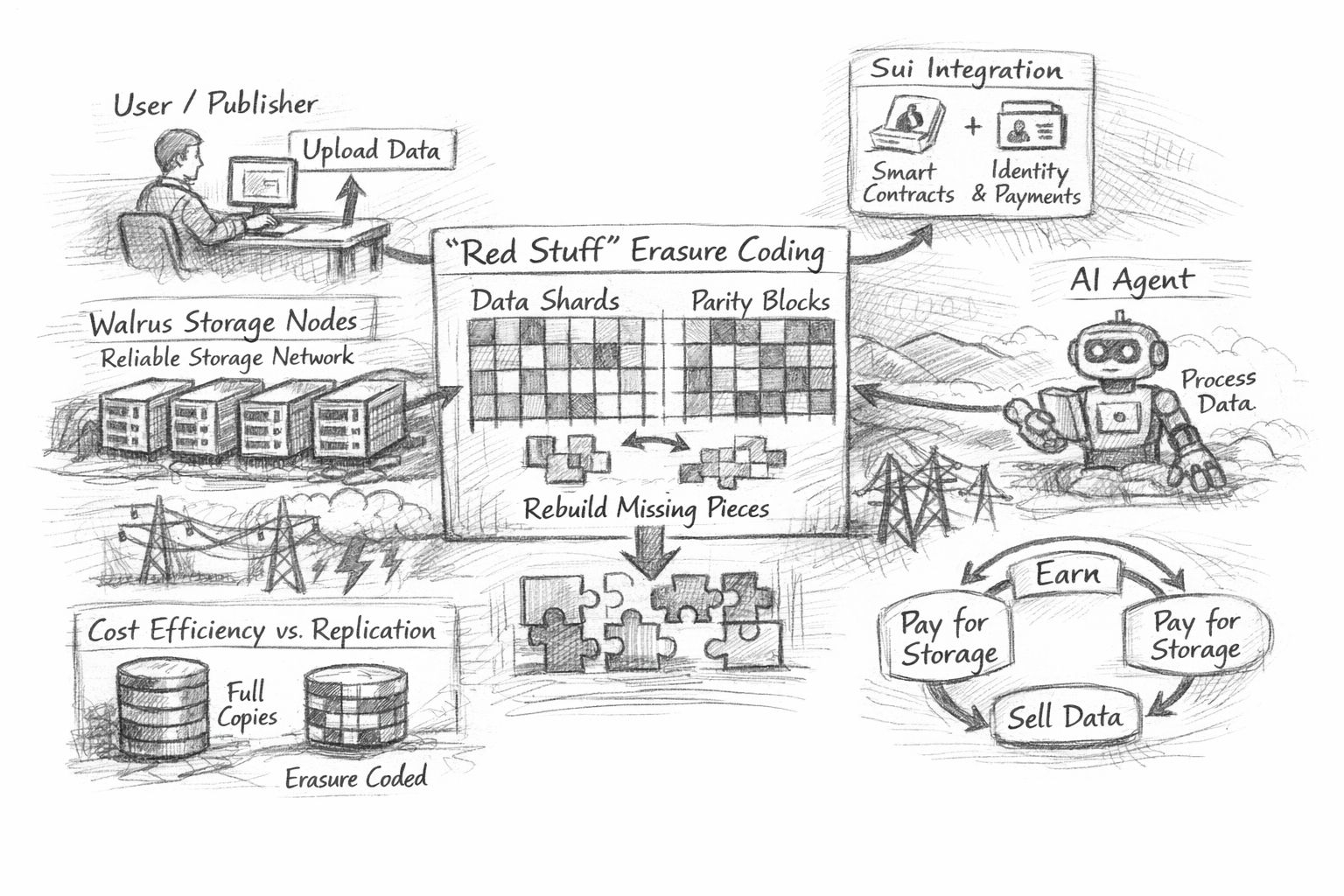
A história técnica do Walrus é construída em torno da resiliência e eficiência nessas condições. Em um nível alto, ele depende da codificação de eliminação—especificamente uma abordagem que chama de “Red Stuff”—para dividir dados em peças e adicionar redundância para que o blob original possa ser reconstruído mesmo se algumas peças estiverem faltando. A intuição é simples: em vez de fazer muitas cópias completas do mesmo arquivo em muitas máquinas, você divide o arquivo em fragmentos e armazena um conjunto estruturado de fragmentos extras que podem “preencher as lacunas” quando o mundo se comporta mal. O Walrus descreve o Red Stuff como um protocolo de codificação de eliminação bidimensional projetado para manter a disponibilidade alta enquanto reduz a sobrecarga de armazenamento que vem da replicação pura, e para suportar a recuperação quando os nós mudam.
Isso é importante porque a linha de base para armazenamento descentralizado não é um ambiente de laboratório limpo; é o caos do dia a dia. Operadores mudam. O hardware falha de maneiras pouco interessantes: discos se degradam, fontes de alimentação falham, redes flutuam. A conectividade é irregular na borda e apenas “boa o suficiente” em muitos lugares onde as equipes realmente implantam. Interrupções regionais ocorrem, às vezes por causa de eventos naturais, às vezes por causa de provedores de upstream, às vezes por razões que ninguém pode explicar completamente no momento. Uma rede de armazenamento que assume uma participação estável é uma rede de armazenamento que irá decepcioná-lo precisamente quando você mais precisa dela. A pesquisa e documentação do Walrus colocam os custos de churn e recuperação perto do centro do problema de design, que é um sinal silencioso de seriedade: é mais fácil demonstrar um upload em um caminho feliz do que projetar um sistema que trate o churn como normal.
O ângulo da eficiência não se trata apenas de economizar dinheiro no abstrato; trata-se de tornar produtos reais viáveis. O armazenamento baseado em replicação é basicamente: duplicar o blob inteiro muitas vezes, depois confiar no fato de que pelo menos algumas cópias não desaparecerão. É simples, mas fica caro quando o uso cresce. A sobrecarga não é uma métrica “opcional” no armazenamento—ela controla o que é prático: manter mídias online para um aplicativo, enviar atualizações de jogos regularmente ou arquivar grandes dados sem pagar para reuploadá-los repetidamente. O desempenho de recuperação é igualmente decisivo. Se os desenvolvedores tiverem que escolher entre descentralização e experiência do usuário, a maioria escolherá silenciosamente a experiência do usuário, especialmente quando suas reputações e SLAs estão em jogo. As descrições públicas do Walrus sobre o Red Stuff se concentram em reduzir os compromissos tradicionais: diminuindo a sobrecarga em relação à replicação completa, mantendo a recuperação leve o suficiente para que o churn não apague as economias.
É também aqui que a estrutura “agentes de IA como atores econômicos” se torna mais do que um slogan, se for levada a sério. O gargalo prático para sistemas agentes não é apenas raciocínio ou execução; é estado, memória e proveniência. Agentes produzem artefatos: conjuntos de dados intermediários, saídas de modelos, logs, rastros, resultados de ferramentas e a lenta acumulação de contexto que os torna úteis ao longo do tempo. Se esses artefatos viverem em buckets centralizados, então a economia de agentes herda as mesmas suposições frágeis da infraestrutura Web2: um único administrador pode revogar o acesso, os preços podem mudar sem aviso, contas podem ser congeladas e a continuidade da “vida” do agente depende de um relacionamento com o fornecedor. O Walrus defende um mundo onde esses artefatos são armazenados em uma camada descentralizada e podem ser recuperados e verificados de forma confiável, criando as condições para que os dados sejam compartilhados, autorizados e monetizados de maneira mais nativa. Seu próprio posicionamento enfatiza mercados de dados abertos e fluxos de trabalho orientados a agentes, e destacou projetos de agentes como primeiros adotantes.
A monetização, neste contexto, é menos sobre transformar cada byte em uma commodity especulativa e mais sobre tornar o acesso aos dados legível e aplicável. Para um agente de IA se tornar um ator econômico, ele precisa de uma maneira de pagar pelo armazenamento, pagar pela recuperação e potencialmente ganhar com os artefatos que produz—preservando controle suficiente para que o “ativo” não seja instantaneamente copiado e despojado de valor. Os detalhes do design de mercado ainda são um campo aberto na indústria, mas o armazenamento é uma das poucas camadas onde as restrições forçam clareza: alguém paga pela persistência; alguém paga pelo serviço; alguém arca com o risco operacional. O design de token e pagamento do Walrus é apresentado como uma tentativa de tornar os custos de armazenamento previsíveis na prática, incluindo um mecanismo descrito como mantendo os custos estáveis em termos fiduciários ao longo de um período fixo de armazenamento, que é o tipo de decisão pouco glamourosa que as equipes de infraestrutura tendem a apreciar.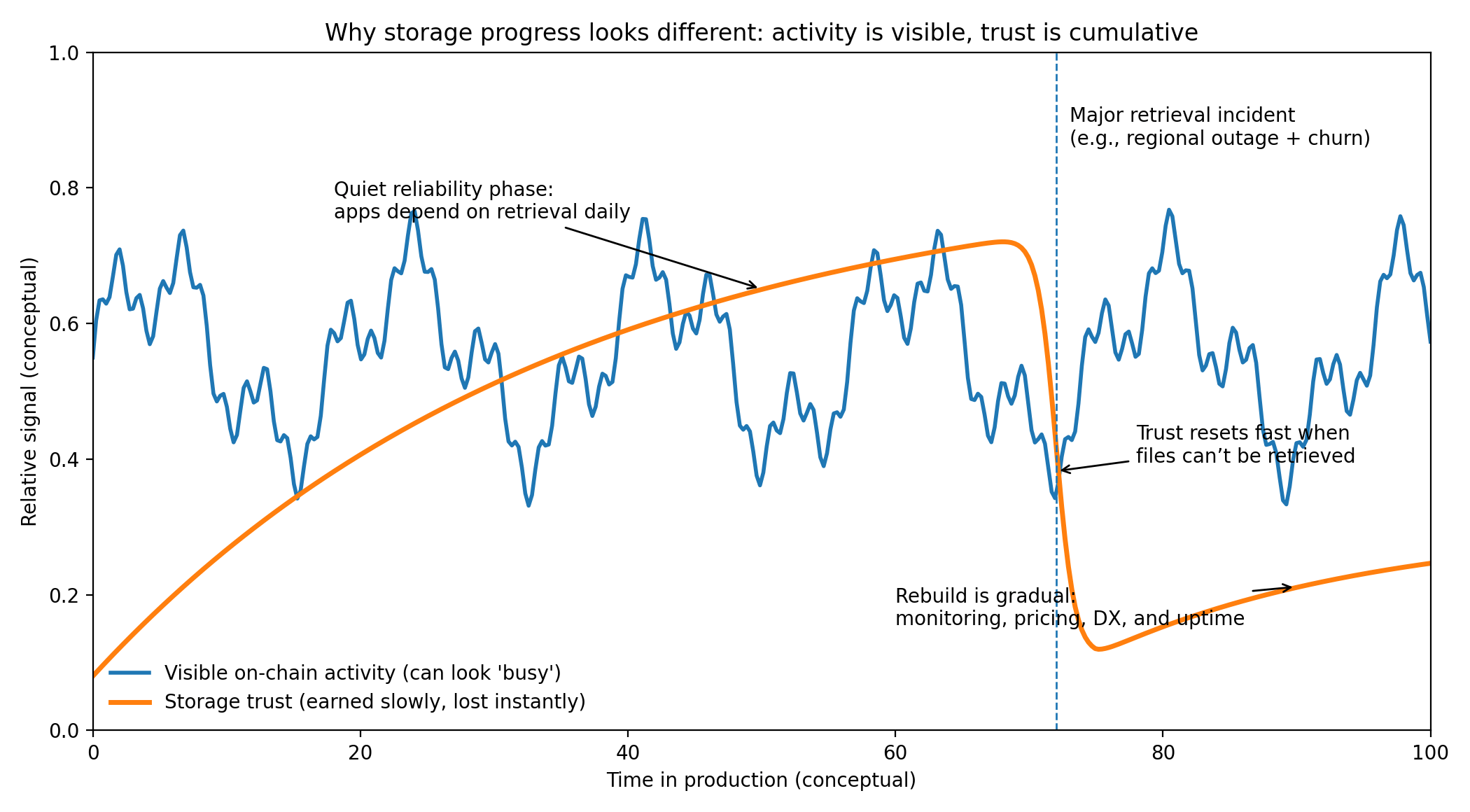
O Walrus também está intimamente associado ao ecossistema Sui, e esse ancoramento não é apenas branding. Quando uma camada de armazenamento é integrada com uma camada de execução, algumas fricções práticas se tornam mais suaves. Os pagamentos se tornam compostos em vez de estarem de lado. Padrões de identidade e acesso podem ser expressos com os mesmos primitivos que os desenvolvedores já usam para aplicativos. Referências a blobs armazenados podem viver em cadeia de uma maneira que é mais fácil de verificar e automatizar. No artigo acadêmico do Walrus, os autores descrevem explicitamente o sistema como combinando a abordagem de codificação Red Stuff com a blockchain Sui, sugerindo um design onde a cadeia desempenha um papel de coordenação e verificação enquanto a rede de armazenamento faz o trabalho pesado com os dados. Esse tipo de acoplamento pode ser uma verdadeira vantagem para a experiência do desenvolvedor, se permanecer simples e evitar forçar as equipes a fazer acrobacias operacionais incomuns.
Um exemplo de uso fundamentado ajuda a evitar que isso se desvie para abstrações. Imagine uma pequena equipe construindo uma aplicação rica em mídia—digamos, um produto que permite aos usuários publicar conteúdo longo com áudio embutido, imagens e arquivos para download. Em uma configuração centralizada, a equipe usa um bucket de nuvem e uma CDN e espera que nunca precise migrar. Em uma configuração descentralizada que realmente visa ser infraestrutura de produção, a equipe deseja duas coisas que parecem chatas, mas são existenciais: recuperação previsível e custos previsíveis. Eles não querem explicar aos usuários por que um post antigo está faltando um anexo porque um nó desapareceu, ou por que um pequeno pico no uso fez as contas de armazenamento explodirem. O Walrus se apresenta como uma camada de armazenamento onde a aplicação pode fazer upload de grandes blobs, referenciá-los de forma confiável e continuar a servi-los mesmo à medida que operadores de armazenamento individuais vão e vêm, porque o sistema assume que esse tipo de churn acontecerá.
Tudo isso colapsa, no entanto, se a confiança operacional não for conquistada da maneira que as equipes de infraestrutura exigem. As equipes não migram dados críticos porque um protocolo tem um artigo interessante; elas migram quando a história do dia a dia parece segura. Isso geralmente significa superfícies claras de monitoramento e depuração, SDKs estáveis e um modelo de preços que não requer gerenciamento constante do tesouro para evitar surpresas. Isso significa que os modos de falha são bem compreendidos e os caminhos de recuperação não são heróicos. Também significa que a camada social importa: alguém tem que estar de plantão, alguém tem que publicar post-mortems, alguém tem que manter a experiência do desenvolvedor coerente à medida que o sistema evolui. As atualizações do próprio Walrus enfatizam o trabalho em nível de produto, como ferramentas para desenvolvedores e tornando os uploads confiáveis mesmo sob conexões móveis irregulares, o que fala mais sobre essa realidade operacional do que muitas narrativas brilhantes.
A visão equilibrada é que a adoção de armazenamento é lenta por boas razões. Os custos de troca são altos porque os dados têm gravidade e porque as penalidades por erros são permanentes de uma maneira que as interrupções de computação muitas vezes não são. Mesmo que um sistema de armazenamento funcione bem no papel, a maioria das equipes será cautelosa. Elas o executarão ao lado de sua configuração atual, o testarão rigorosamente para ver como se comporta sob estresse e só então moverão os dados verdadeiramente importantes. O Walrus terá sucesso se se tornar uma infraestrutura silenciosa—menos notada como um protocolo e mais como uma suposição confiável. Se a rede puder continuar a fazer o trabalho não celebrado de reter e servir grandes blobs através de churn, interrupções e disfunções ordinárias, então a visão mais ambiciosa—agentes que armazenam, recuperam e monetizam artefatos como parte de fluxos de trabalho econômicos reais—terá uma base credível para construir. Se não puder, nenhuma quantidade de atividade em cadeia compensará, porque o armazenamento é uma das poucas camadas onde a verdade chega não em anúncios, mas na longa e inusitada extensão onde nada dá errado.

