
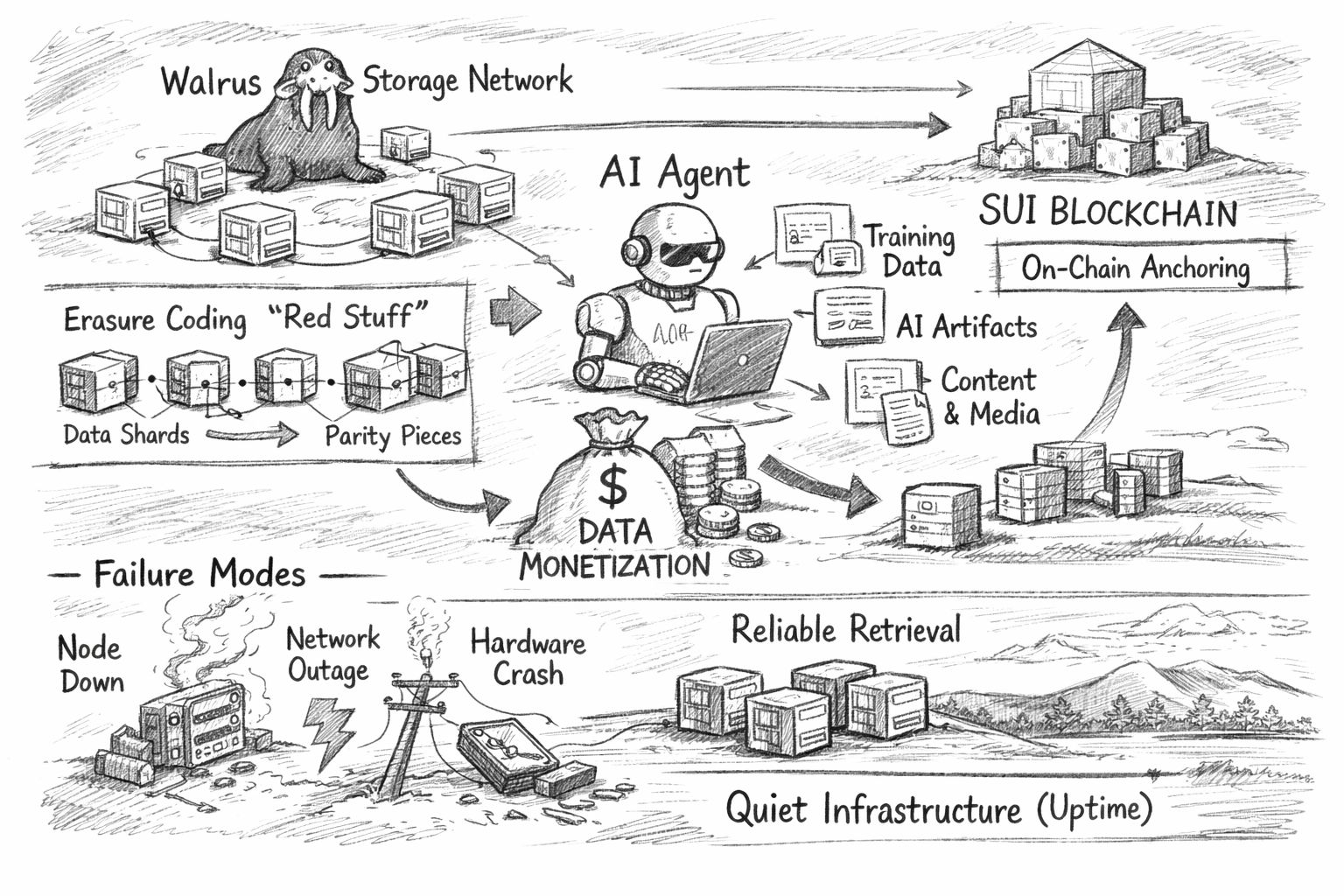
@Walrus 🦭/acc Los sistemas criptográficos tienden a celebrar lo que pueden contar. TPS, direcciones activas diarias, tarifas y nuevos contratos pueden decirte algo, pero también pueden engañar. Es fácil confundir “está pasando mucho” con “se está logrando un progreso real”. El almacenamiento gana confianza en un cronograma diferente. Un sistema de computación puede parecer ocupado durante semanas y aún así fallar la primera vez que un producto real depende de él bajo presión. Un sistema de almacenamiento se convierte en “real” solo cuando las aplicaciones dependen de él día tras día, cuando la recuperación sigue funcionando a través de las condiciones desordenadas que los equipos tratan de no pensar, y cuando la historia operativa es lo suficientemente aburrida como para que la gente deje de hablar de ella. Ese es el contexto para el enfoque de Walrus. Walrus es básicamente una red de almacenamiento descentralizada para grandes “blobs” de datos, diseñada para hacer que la recuperación sea confiable. Está dirigida a aplicaciones pesadas en contenido y datos donde los archivos son grandes, llegan constantemente o importan demasiado para arriesgarse. El mensaje es claro: el almacenamiento no es un complemento, es fundamental, porque el inconveniente de arruinarlo es mucho mayor de lo que la gente espera. Walrus también se enmarca como una fundación para “mercados de datos” en una economía modelada por IA, donde los datos y los artefactos derivados de ellos pueden ser controlados, accedidos y pagados de una manera más nativa. Ese enmarcado es explícito en sus materiales públicos, que enfatizan los datos como un activo y destacan los casos de uso de agentes de IA junto a cargas de trabajo de contenido y medios más familiares.
Vale la pena reflexionar sobre por qué el almacenamiento es una promesa más difícil que la computación. Los problemas de computación son generalmente locales y solucionables: vuelves a ejecutar el trabajo, cambias la máquina, y una interrupción se convierte en un informe y un parche. Los problemas de almacenamiento se sienten más pesados porque los datos perdidos pueden estar perdidos para siempre. Puedes simular actividad de computación al spamear llamadas baratas, pero no puedes simular años de recuperación confiable. Un equipo serio no le importa que una red de almacenamiento pueda aceptar cargas hoy si no están seguros de que esas cargas aún serán recuperables el próximo trimestre, el próximo año, y después de que los operadores originales se hayan ido. Esa es la razón por la cual la confianza en el almacenamiento se gana lentamente y se pierde instantáneamente. También es por eso que la adopción tiende a llegar más tarde de lo que las narrativas sugieren. Los costos de cambio son altos, y el modo de fallo es brutal: no solo rompes una aplicación, rompes su memoria.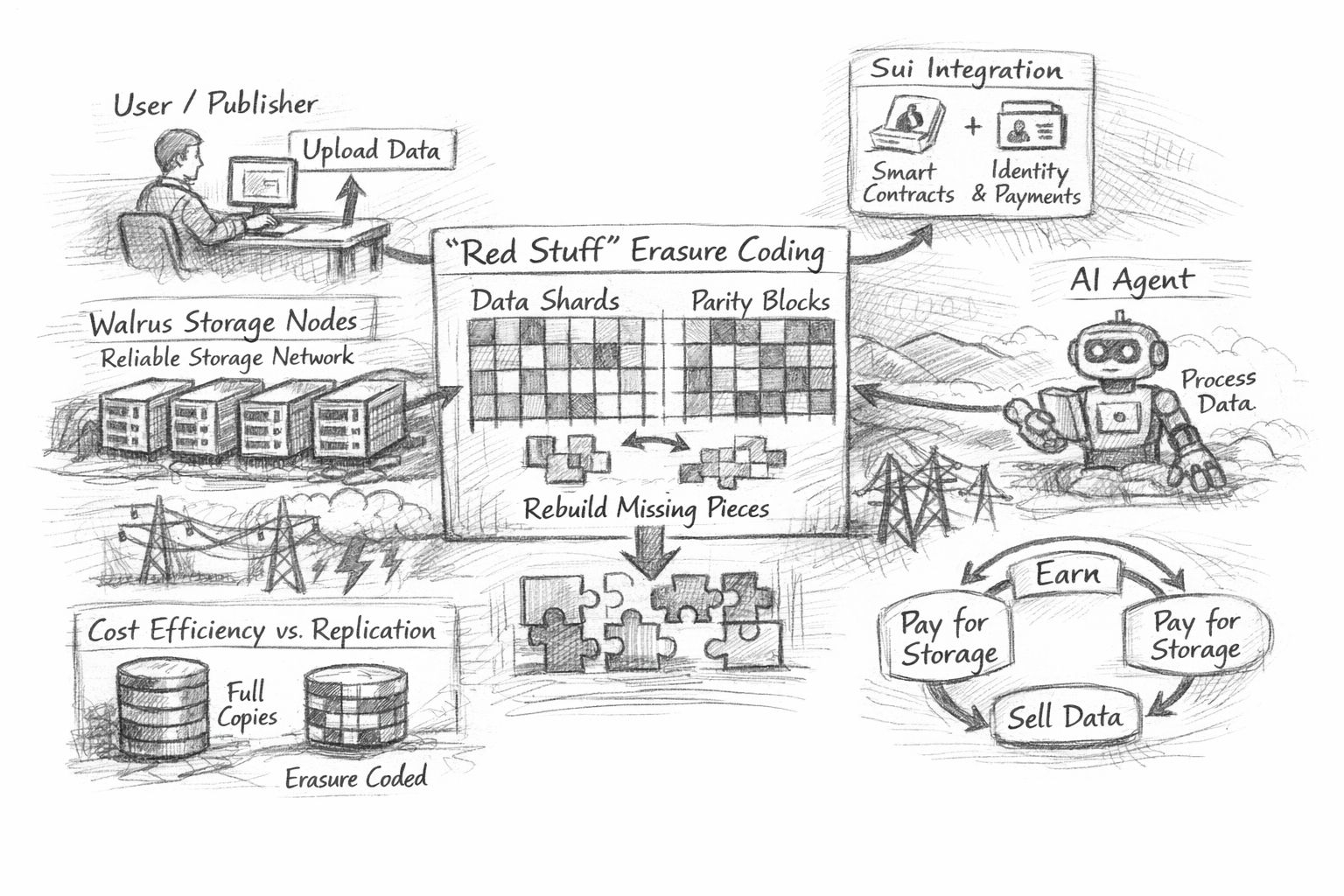
La historia técnica de Walrus se basa en la resiliencia y eficiencia bajo esas condiciones. A un alto nivel, se basa en la codificación de borrado—específicamente un enfoque que llama “Red Stuff”—para dividir los datos en piezas y agregar redundancia para que el blob original pueda ser reconstruido incluso si faltan algunas piezas. La intuición es simple: en lugar de hacer muchas copias completas del mismo archivo en muchas máquinas, divides el archivo en fragmentos y almacenas un conjunto estructurado de fragmentos extra que pueden “llenar los vacíos” cuando el mundo se comporta mal. Walrus describe Red Stuff como un protocolo de codificación de borrado bidimensional diseñado para mantener alta la disponibilidad mientras reduce los costos de almacenamiento que vienen de la replicación pura, y para soportar la recuperación cuando los nodos cambian.
Esto importa porque la base para el almacenamiento descentralizado no es un entorno de laboratorio limpio; es el caos cotidiano. Los operadores cambian. El hardware falla de maneras poco interesantes: los discos se degradan, las fuentes de alimentación mueren, las redes fluctúan. La conectividad es irregular en los bordes y simplemente “suficientemente buena” en muchos lugares donde los equipos realmente despliegan. Las interrupciones regionales ocurren, a veces debido a eventos naturales, a veces debido a proveedores upstream, a veces por razones que nadie puede explicar completamente en el momento. Una red de almacenamiento que asume una participación estable es una red de almacenamiento que te decepcionará precisamente cuando más la necesites. La investigación y documentación de Walrus colocan los costos de cambio y recuperación cerca del centro del problema de diseño, lo que es una señal tranquila de seriedad: es más fácil demostrar una carga de ruta feliz que ingenierar un sistema que trate el cambio como normal.
El ángulo de eficiencia no se trata solo de ahorrar dinero en abstracto; se trata de hacer que los productos reales sean factibles. El almacenamiento basado en replicación es básicamente: duplicar el blob entero muchas veces, luego confiar en el hecho de que al menos algunas copias no desaparecerán. Es simple, pero se vuelve costoso cuando el uso crece. Los costos indirectos no son una métrica “opcional” en el almacenamiento—controlan lo que es práctico: mantener los medios en línea para una aplicación, enviar actualizaciones de juegos regularmente, o archivar grandes datos sin pagar por volver a cargarlos una y otra vez. El rendimiento de recuperación es igualmente decisivo. Si los desarrolladores tienen que elegir entre descentralización y experiencia del usuario, la mayoría elegirá silenciosamente la experiencia del usuario, especialmente cuando sus reputaciones y SLA están en juego. Las descripciones públicas de Walrus sobre Red Stuff se centran en reducir los compromisos tradicionales: disminuir los costos indirectos en relación con la replicación completa mientras se mantiene la recuperación lo suficientemente ligera como para que el cambio no borre los ahorros.
Este también es el lugar donde el marco de “los agentes de IA como actores económicos” se convierte en más que un eslogan, si se toma en serio. El cuello de botella práctico para los sistemas agentes no es solo el razonamiento o la ejecución; es el estado, la memoria y la procedencia. Los agentes producen artefactos: conjuntos de datos intermedios, salidas de modelos, registros, trazas, resultados de herramientas, y la lenta acumulación de contexto que los hace útiles a lo largo del tiempo. Si esos artefactos viven en buckets centralizados, entonces la economía de agentes hereda las mismas suposiciones frágiles que la infraestructura Web2: un solo administrador puede revocar el acceso, los precios pueden cambiar sin previo aviso, las cuentas pueden ser congeladas, y la continuidad de la “vida” del agente depende de una relación con el proveedor. Walrus aboga por un mundo donde estos artefactos se almacenan en una capa descentralizada y pueden ser recuperados y verificados de manera confiable, creando las condiciones para que los datos sean compartidos, autorizados y monetizados de una manera más nativa. Su propia posición enfatiza mercados de datos abiertos y flujos de trabajo orientados a agentes, y ha destacado proyectos de agentes como primeros adoptantes.
La monetización, en este contexto, es menos sobre convertir cada byte en una mercancía especulativa y más sobre hacer que el acceso a los datos sea legible y aplicable. Para que un agente de IA se convierta en un actor económico, necesita una forma de pagar por el almacenamiento, pagar por la recuperación y potencialmente ganar a partir de los artefactos que produce—mientras conserva suficiente control para que el “activo” no sea copiado instantáneamente y despojado de valor. Los detalles del diseño del mercado siguen siendo un campo abierto en toda la industria, pero el almacenamiento es una de las pocas capas donde las restricciones obligan a la claridad: alguien paga por la persistencia; alguien paga por el servicio; alguien asume el riesgo operativo. El diseño del token y del pago de Walrus se presenta como un intento de hacer que los costos de almacenamiento sean predecibles en la práctica, incluyendo un mecanismo descrito como mantener los costos estables en términos fiduciarios durante un período de almacenamiento fijo, que es el tipo de decisión poco glamorosa que los equipos de infraestructura tienden a apreciar.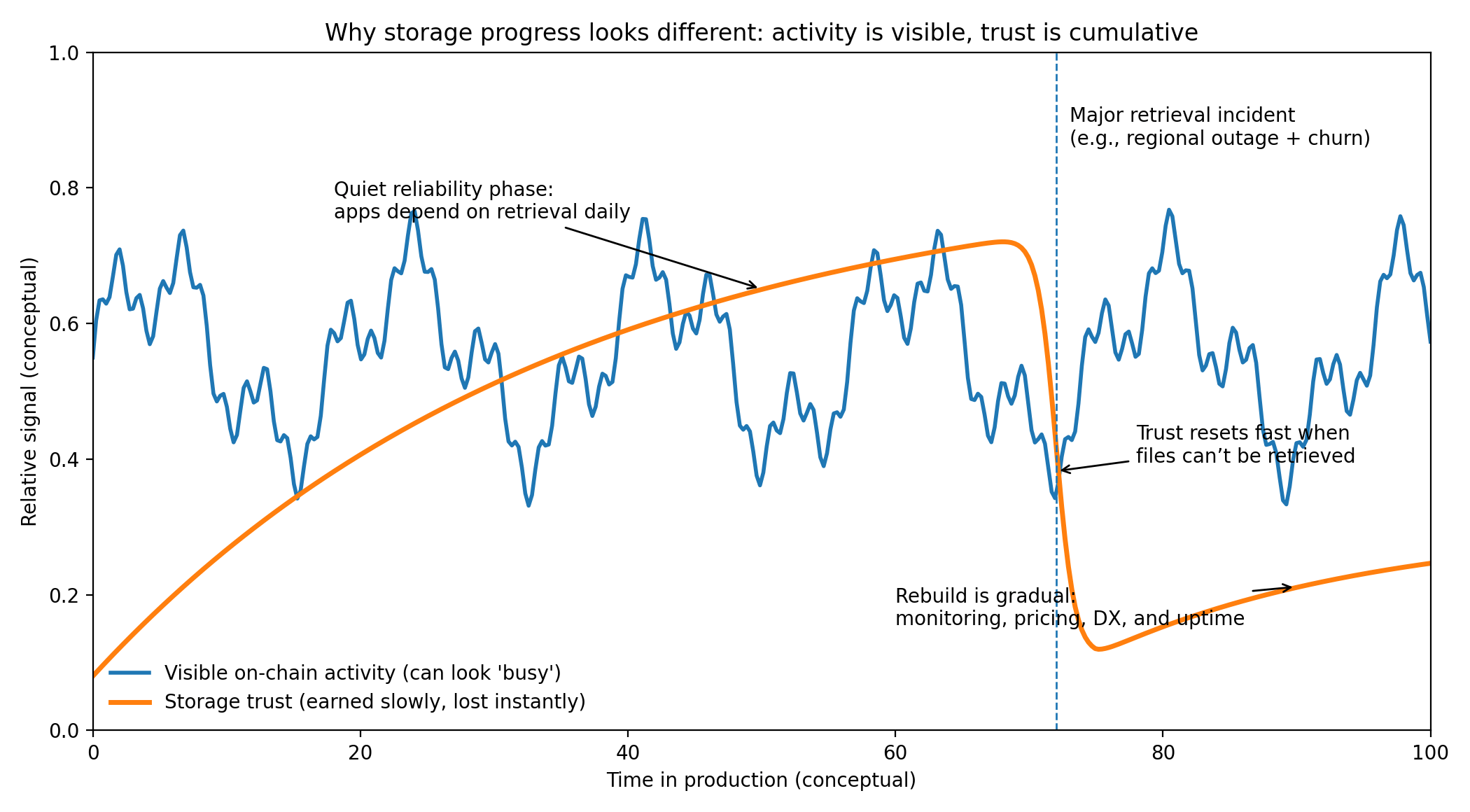
Walrus también está estrechamente asociado con el ecosistema Sui, y ese anclaje no es solo una cuestión de marca. Cuando una capa de almacenamiento está integrada con una capa de ejecución, algunas fricciones prácticas se suavizan. Los pagos se vuelven componibles en lugar de estar al margen. Los patrones de identidad y acceso pueden expresarse con los mismos primitivos que los desarrolladores ya utilizan para aplicaciones. Las referencias a blobs almacenados pueden vivir en la cadena de una manera que es más fácil de verificar y automatizar. En el documento académico de Walrus, los autores describen explícitamente el sistema como una combinación del enfoque de codificación de Red Stuff con la blockchain de Sui, sugiriendo un diseño donde la cadena desempeña un papel de coordinación y verificación mientras que la red de almacenamiento hace el trabajo pesado sobre los datos. Ese tipo de acoplamiento puede ser una verdadera ventaja para la experiencia del desarrollador, si se mantiene simple y evita forzar a los equipos a realizar gimnasia operativa inusual.
Un ejemplo de uso concreto ayuda a evitar que esto se desvíe hacia abstracciones. Imagina un pequeño equipo construyendo una aplicación con mucho contenido multimedia—digamos, un producto que permite a los usuarios publicar contenido de formato largo con audio incrustado, imágenes y archivos descargables. En una configuración centralizada, el equipo utiliza un bucket en la nube y un CDN y espera que nunca tenga que migrar. En una configuración descentralizada que realmente aspira a ser infraestructura de producción, el equipo quiere dos cosas que suenan aburridas pero son existenciales: recuperación predecible y costos predecibles. No quieren explicar a los usuarios por qué una publicación antigua carece de un archivo adjunto porque un nodo desapareció, o por qué un pequeño aumento en el uso causó que las facturas de almacenamiento explotaran. Walrus se presenta como una capa de almacenamiento donde la aplicación puede cargar grandes blobs, referenciarlos de manera confiable y seguir sirviéndolos incluso cuando los operadores de almacenamiento individuales van y vienen, porque el sistema asume que ese tipo de cambio sucederá.
Todo esto colapsa, sin embargo, si la confianza operativa no se gana de la manera que los equipos de infraestructura requieren. Los equipos no migran datos críticos porque un protocolo tiene un documento interesante; migran cuando la historia del día a día se siente segura. Eso generalmente significa superficies de monitoreo y depuración claras, SDKs estables y un modelo de precios que no requiera gestión constante del tesoro para evitar sorpresas. Significa que los modos de fallo están bien entendidos y los caminos de recuperación no son heroicos. También significa que la capa social importa: alguien tiene que estar de guardia, alguien tiene que publicar postmortems, alguien tiene que mantener la experiencia del desarrollador coherente a medida que el sistema evoluciona. Las propias actualizaciones de Walrus enfatizan el trabajo a nivel de producto como herramientas para desarrolladores y hacer que las cargas sean confiables incluso bajo conexiones móviles irregulares, lo que habla de esta realidad operativa más que muchas narrativas brillantes.
La visión equilibrada es que la adopción del almacenamiento es lenta por buenas razones. Los costos de cambio son altos porque los datos tienen gravedad, y porque las penalizaciones por errores son permanentes de una manera que las interrupciones computacionales a menudo no lo son. Incluso si un sistema de almacenamiento funciona bien en papel, la mayoría de los equipos serán cautelosos. Lo ejecutarán junto a su configuración actual, lo presionarán para ver cómo se comporta bajo estrés, y solo entonces moverán los datos realmente importantes. Walrus tiene éxito si se convierte en una infraestructura silenciosa—menos notada como un protocolo y más como una suposición confiable. Si la red puede seguir haciendo el trabajo no celebrado de retener y servir grandes blobs a través del cambio, interrupciones y disfunciones ordinarias, entonces la visión más ambiciosa—agentes que almacenan, recuperan y monetizan artefactos como parte de flujos de trabajo económicos reales—tiene una base creíble sobre la cual construir. Si no puede, ninguna cantidad de actividad en la cadena compensará, porque el almacenamiento es una de las pocas capas donde la verdad llega no en anuncios, sino en la larga y poco emocionante extensión donde nada sale mal.

