
Todo el mundo asume que los identificadores de blobs son simples: hashea los datos, usa eso como ID. Walrus demuestra que esa forma de pensar es demasiado pequeña. La verdadera identidad de un blob incluye tanto el hash de los datos como los metadatos de codificación. Esta única elección de diseño permite la verificación, la deduplicación, el versionado y la seguridad bizantina, todo simultáneamente.
El problema de identidad solo con hash
El almacenamiento de blobs tradicional utiliza identificadores basados en el contenido: hashea los datos, esa es tu ID. Simple, elegante, obvio.
Aquí está lo que se rompe: cambios en la codificación. Un blob almacenado con Reed-Solomon (10,5) tiene una codificación diferente que los mismos datos almacenados con Reed-Solomon (20,10). Son los mismos datos lógicos pero requieren procesos de recuperación diferentes.
Usando IDs solo hash, estos son idénticos. Los validadores recuperan el blob y no tienen forma de saber qué codificación deberían reconstruir. Los clientes que solicitan el blob no saben qué codificación esperar.
Esto forza elecciones costosas: almacenar múltiples codificaciones de los mismos datos (desperdicio), o hacer que los clientes conozcan la codificación fuera de banda (frágil y propenso a errores).
La magia del ID de Blob de Morsa es mejor.
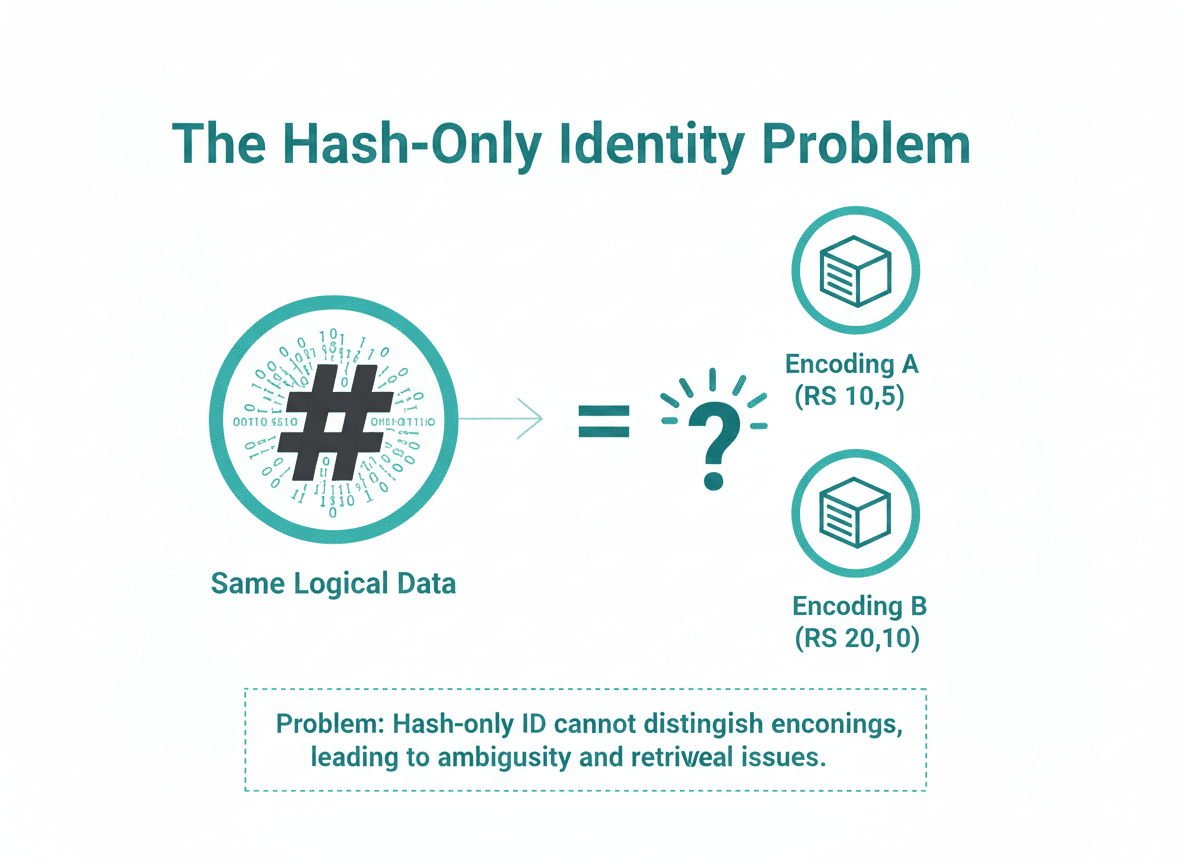
Compromiso de Hash + Metadatos = Identidad Única
Los IDs de Blob de Morsa son más sofisticados: combinan el hash de contenido con metadatos de codificación. La ID identifica de manera única no solo los datos, sino también el esquema de codificación exacto y los parámetros.
Aquí está lo que esto te ofrece:
Primero, seguridad bizantina. El ID de Blob prueba que los validadores están almacenando la codificación exacta comprometida. Un validador que afirma almacenar un blob con ID X debe servir datos que se re-codifiquen para producir ID X. No pueden afirmar que están almacenando los datos con una codificación diferente.
Segundo, desduplicación. Si los mismos datos se almacenan con múltiples codificaciones, los múltiples IDs hacen eso visible. Puedes desduplicar los datos subyacentes mientras mantienes IDs de Blob distintos para diferentes esquemas de codificación.
Tercero, simplicidad de verificación. Cuando recuperas un blob, la ID te dice exactamente qué codificación esperar. No necesitas negociar con validadores o verificar por separado. La ID en sí es el ancla de verificación.
Cuarto, versionado. Si vuelves a codificar un blob a un esquema diferente, obtiene un nuevo ID. La historia de las codificaciones es visible y rastreable.
Cómo Funciona Esto Arquitectónicamente
El ID de Blob se calcula como: Hash(datos || esquema_de_codificación || parámetros_de_codificación)
Esto produce un identificador único que captura:
Qué datos se almacenan (a través del hash)
Cómo está codificado (Reed-Solomon con parámetros específicos)
Cuántos fragmentos (valores k y n)
Asignaciones de comité e información de época
Cada pieza de información que afecta la recuperación y verificación es parte de la ID.
Cuando solicitas un blob con ID X, la red sabe:
Exactamente qué datos quieres
Exactamente cómo está codificado
Exactamente qué validadores deberían tener fragmentos
Exactamente cómo verificarlo
Sin ambigüedad. Sin negociación.
Seguridad Bizantina a Través de la Identidad
Aquí es donde la elegancia del diseño se muestra: el ID de Blob en sí es prueba criptográfica de seguridad bizantina.
Un validador que afirma almacenar un blob con ID X se está comprometiendo implícitamente a:
Tener datos que hashean al hash de contenido en X
Usar el esquema de codificación exacto especificado en X
Mantener los parámetros de fragmento exactos en X
Si se desvían—diferente codificación, diferentes parámetros, datos corruptos—la verificación de ID falla. Son atrapados.
La ID es el mecanismo de seguridad bizantina. No es una firma de los validadores. No es un compromiso de quórum. Es la unicidad matemática de la codificación.
Desduplicación Sin Ambigüedad
Tradicionalmente, la desduplicación crea problemas: si almacenas datos en cadena dos veces con diferentes codificaciones, ¿cómo saben los validadores qué versión servir?
Con la magia de ID de Blob, esto es claro. Los datos almacenados con codificación A tienen ID X. Los datos almacenados con codificación B tienen ID Y. A pesar de que son los mismos bytes subyacentes, los IDs los hacen distintos.
Los validadores pueden desduplicar los datos en crudo mientras mantienen IDs de Blob separados. El sistema sabe qué codificación requiere cada ID.
Esto ahorra almacenamiento mientras mantiene claridad.
Verificación Sin Rondas Adicionales
Los sistemas tradicionales necesitan rondas de verificación adicionales: solicitar blob, obtener datos, verificar que coincidan con tus expectativas, confirmar que la codificación sea correcta.
La magia del ID de Blob hace esto instantáneo. La ID te dice qué esperar. Los datos devueltos coinciden con la ID o no. Una verificación, resultado determinista.
Esto es lo que hace que la verificación de lectura sea eficiente. La ID está precomputada. La verificación es comprobar si los datos devueltos hashean y codifican para coincidir con la ID. Listo.
Metadatos como Restricción de Seguridad
Los metadatos de codificación no son solo informativos. Es una restricción de seguridad que los validadores no pueden violar.
¿Quieres usar menos fragmentos para reducir el almacenamiento? Eso cambia el ID de Blob. Ya no estás almacenando el mismo blob. Estás almacenando un blob diferente con un ID diferente.
¿Quieres cambiar esquemas de codificación? Nuevo ID. Blob diferente.
Esto crea responsabilidad. No puedes degradar silenciosamente la seguridad de un blob utilizando menos fragmentos. El cambio es visible a través del cambio de ID.
Versionado y Evolución
A medida que los blobs envejecen, es posible que desees volver a codificarlos. Quizás cambia el tamaño del comité. Quizás optimizas para una tolerancia a fallos diferente. Creas un nuevo ID de Blob para la nueva codificación.
El sistema mantiene ambas versiones. Puedes rastrear cuándo los blobs se movieron entre codificaciones. Puedes probar la evolución de la codificación de cada blob.
Esto es transparencia radical en comparación con el almacenamiento tradicional donde los cambios de codificación son invisibles.
Eficiencia Computacional
Aquí está la victoria práctica: calcular el ID de Blob es barato. Hashea los datos una vez, añade metadatos, hashea de nuevo. Sobrecarga negligible.
La verificación usando la ID también es barata. Compara un hash contra la ID. Listo.
Esto es diferente de los sistemas que requieren verificación de firma, chequeos de quórum o múltiples rondas. La verificación del ID de Blob es O(1) y casi gratuita.
Prevención de Ataques de Codificación
Los validadores bizantinos podrían intentar servir datos codificados de manera diferente a lo comprometido. Con identificadores tradicionales, esto es difícil de detectar.
Con los IDs de Blob, es imposible. La ID especifica de manera única la codificación. Servir diferentes codificaciones rompe la ID. El ataque es detectable inmediatamente.
Comparación con Almacenamiento Dirigido por Contenido
Dirigido por contenido (solo hash):
IDs Simples
Ambiguo cuando los datos tienen múltiples codificaciones
Requiere información de codificación fuera de banda
Vulnerable a ataques de codificación
Difícil rastrear la evolución de la codificación
Magia de ID de Blob:
Las IDs codifican metadatos
Especificación de codificación no ambigua
Blobs auto-descriptivos
Ataques de codificación detectados inmediatamente
La evolución es visible y rastreable
La diferencia es categórica.
Implicaciones del Mundo Real
Para aplicaciones que almacenan blobs:
La desduplicación es clara (diferentes codificaciones tienen diferentes IDs)
La codificación es auto-descriptiva (la ID te dice cómo recuperar)
La evolución es rastreable (nueva codificación = nuevo ID)
La seguridad es verificable (la ID es prueba de seguridad bizantina)
No más suposiciones sobre qué codificación está activa. No más asumiendo metadatos de codificación. No más preguntándose si los validadores cambiaron algo en silencio.
La Psicología de la Claridad
Hay algo satisfactorio en identificadores que son auto-descriptivos. La ID te dice todo lo que necesitas saber sobre lo que estás recuperando.
Esto desplaza la infraestructura de "confía en que el validador te dijo la verdad" a "el identificador en sí mismo es prueba de lo que estás obteniendo."
La magia del ID de Blob de Morsa transforma la identidad del blob de un simple hash de contenido a una especificación comprensiva que incluye datos, codificación y metadatos. Esta única elección de diseño permite seguridad bizantina, desduplicación, simplicidad de verificación y evolución de codificación—todo simultáneamente.
Para almacenamiento descentralizado que necesita ser transparente sobre lo que está almacenando y cómo lo está codificando, esto es fundamental. El ID de Blob se convierte en tu prueba de que los datos están almacenados correctamente, codificados de manera segura y verificados completamente. La Morsa demuestra que los identificadores simples son demasiado simples. Los identificadores inteligentes son lo que permiten una infraestructura que realmente es confiable.

