昨天晚上阿祖在家干了一件又无聊又现实的事:给自己常用的钱包做“网络大扫除”。
MetaMask、Rabby、OKX Wallet 一路点下来,Network List 里塞满了各种“ Mainnet”“ Chain”“ L2”,Chain ID 从 1、56 到 137、42161、8453,一屏滑不完。乍一看很繁荣,像是“多链时代”的证据,仔细一想有点荒谬:对开发者来说,绝大多数只是“便宜一点的 EVM”,对普通用户来说只是“多了一个 logo、多了一条 RPC”。
那一刻我突然有点烦:我们真的需要这么多复制粘贴版以太坊吗?如果未来 AI 真要上链,它到底会挑哪一条做自己的“老家”?难道真的是谁 gas 便宜就投奔谁?这个问题在脑子里绕了一圈,我的鼠标又一次停在了一个以前完全没在意过的数字上——Chain ID:2040,后面那行写着 Vanar Mainnet。
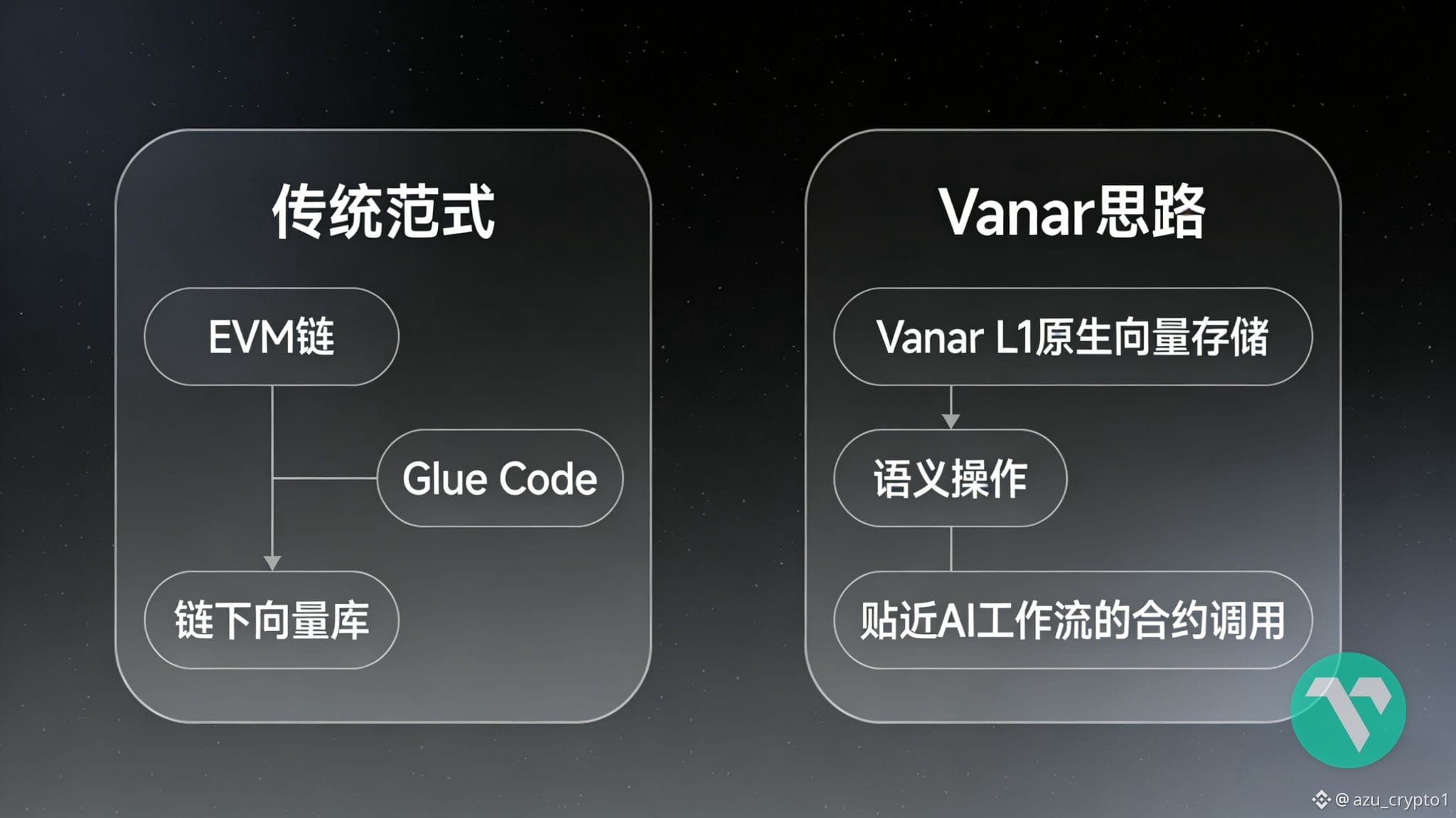
以前我也把它当成“又一条 EVM”,这次我换了个角度问自己:如果 Vanar 只是想做 TPS 更高、Gas 更便宜,根本没必要把自己往“AI-ready L1”这个坑里按。既然它偏要举 AI 这面旗,那它在底层究竟动了哪些别的 EVM 不愿意动、甚至动不了的东西?
先把表层那一层掀开。Vanar 主网从钱包视角看,非常朴素:Network Name 叫 Vanar Mainnet,RPC 和 WSS 正常填,Chain ID 写 2040,原生代币就是 VANRY。你用 Solidity,照样能编、能部署;你用 Hardhat、Foundry、Tenderly,流程也和在以太坊上差不多;区块浏览器一打开,依旧是你熟悉的那种界面。这一切都在释放一个信号:Vanar 没打算在语言和 VM 上折腾开发者,而是选择把所有“新东西”都藏在 EVM 之下。
问题就出在这句“藏在 EVM 之下”。传统公链的默认设定特别简单粗暴:链只负责记账和共识。你往上丢的是钱、NFT、订单簿还是一堆模型参数,在它眼里本质上都是一坨 bytes。它关心的是数量、来源、去向,不关心这东西对机器有没有“意义”;智能全部被扔在链下服务器、私有数据库、项目后台,链顶多记一笔结果哈希或者验个证明。
这套设定跑 DeFi、跑支付没什么问题,一旦把视角切到 AI,就会暴露一个尴尬现实:绝大多数链,对 AI 来说只能当“结算出口”。模型每天跑一堆推理,最后压个哈希上链交差;真正有价值的记忆、语义、上下文,全锁在链外的向量库和日志系统里。AI 想复用昨天的记忆,要先去中心化向量数据库里捞 embedding,再跟链上状态对一下,这哪叫“AI 上链”,更像是“拿 AI 给一条老式账本打补丁”。

Vanar 在底层干的那件不性感、但很要命的事,就是把这个默认设定推翻了。它不是简单喊一句“支持 AI 应用”,而是直接把“记忆”和“语义”当成一等公民来设计链的数据结构。表面上,它还是你熟悉的那条 EVM 链,2040 也只是加网络时的一串参数;真正的差异,是它把向量存储和语义操作写进了主网的能力边界里。
对 AI 来说,真正能用的不是一篇篇原始文档,而是一条条 embedding。很多项目的做法是:链上只存原文或哈希,链下再开一个向量库,中间靠 API 来回跑。Vanar 的思路则很干脆:既然未来大部分长期记忆都会以向量形式存在,那干脆在 L1 里给这类对象腾位置,让它可以被上链、被索引、被按相似度检索,而不是当成毫无语义的 bytes 塞进 storage。在大多数链上,embedding 是外挂;在 Vanar 上,embedding 更像是受链原生规则保护的资产。
这直接牵动了它对状态的布局方式。传统 EVM 更像一个巨大的 key–value 仓库,你知道 key,就能拿到 value,至于这些 value 之间有没有语义关系,虚拟机根本不关心。Vanar 的假设则是:未来链上会充满各种 AI 记忆、任务轨迹、偏好配置,它们需要被按“相似度”和“语义邻近”来召回,而不是靠人类记住一大堆 slot 和 mapping。于是,很多你看不见的地方都朝“语义友好”的方向被改写。
在这条链上,一次合约调用不再只是读写几个存储位置,而是有可能触发一次完整的“召回一批相关记忆→按规则更新→写回链上”的过程。合约表面上还是你习惯的接口签名,但底层对这些记忆的组织方式,已经按 AI 的工作习惯被重新排过版。你可以把差异粗暴地理解成:别的链在账本上记的是钱和状态,Vanar 在账本上尝试记“AI 能直接读懂的记忆块和语义片段”。
当你承认“记忆”和“语义”是正经业务之后,主网的性能标尺自然也会跟着变。只跑转账,你可以拼命做 L2,把状态往外推,甚至可以为了一张 TPS 排行榜牺牲很多工程细节。一旦要承载 AI 的长期记忆和可验证行为记录,你就必须面对更重的节点负载、更大的数据吞吐、更长的时间维度。Vanar 给出的节点规格和实际跑出来的交易体量,其实更像是按照“长线业务”去配的,而不是为某个极端峰值去堆参数。
这种选择从情绪市场的角度看,一点都不讨喜。它讲不出那种“我们 TPS 比谁高多少倍、Gas 比谁便宜多少”的爽文故事,也很难和一堆 meme 币挂在同一条拉盘曲线上。更吸眼球的叙事,永远是某个币翻了几倍、某个应用日活爆了多少,而像 Vanar 这种从底层慢吞吞拧螺丝的,很容易被丢进“无聊”那一栏。
说回那组你在钱包里随手就划过去的参数:2040 和 VANRY。表面上,它们只是“网络编号 + gas 代币”;在上面这套逻辑之下,它们背后藏着另一个维度的含义。2040 不再只是 RPC 配置里的一个整数,而是一个记忆坐标系的标签——当越来越多面向 AI 的应用选择把 embedding、对话轨迹、偏好和策略写进这条链时,2040 会慢慢变成“AI 记忆集中地”的代号:你可以在很多条 EVM 上部署同一个合约、同一个前端,但只有挂在 2040 这套状态上的那一份,是真正被当作“供 AI 长期复用”的那版世界。
VANRY 也不只是“这条 L1 的油”,更像是“AI 读写记忆的电费单”。每一次你写入一段新的语义记忆、压一批向量上链、更新某个 agent 的行为轨迹,消耗掉的那点 gas,一部分是在给安全性付费,让这些记忆不会被随便改写、不至于因为节点下线就蒸发;另一部分是在给长期可用性付费,保证十年、二十年之后,某个智能体还能从 2040 的状态树里把它们翻出来。问题不再只是“这次转账值不值”,而是“这段记忆值不值得被长期保存、并暴露给未来的 AI 继续用”。
如果你相信一件事——2026 年之后,AI 会慢慢从聊天玩具,变成真正的“链上工人”和“长期决策参与者”——那你迟早要问自己:这些工人的记忆到底存在哪条链上?放在中心化向量库里,方便是方便,那是别人的仓库;放在完全不关心语义的公链上,勉强能用,但你得在两边写无数层 glue code 去迎合它“键值世界”的设定。
在一堆复制粘贴出来的 EVM 之间,Vanar 至少做了一件别人懒得做、也不愿意做的事:承认 AI 需要记忆、需要语义、需要长期可验证状态,然后从 Chain ID、数据结构到 gas 计价,把这套需求硬生生写进了一条主网的地基。至于要不要现在就去扫 VANRY,那是你的自由;我能做的,就是先把 2040 这块地板掀开,让你看清楚它下面到底多了一层什么。
