
AI startup selection analysis: Cost and ROI comparison of cloud-based and on-premises GPU deployment (this article is official content provided by C-95, used for summarization and research study)
Here is a detailed cost breakdown for cloud-based and on-premises (on-prem) GPU deployment.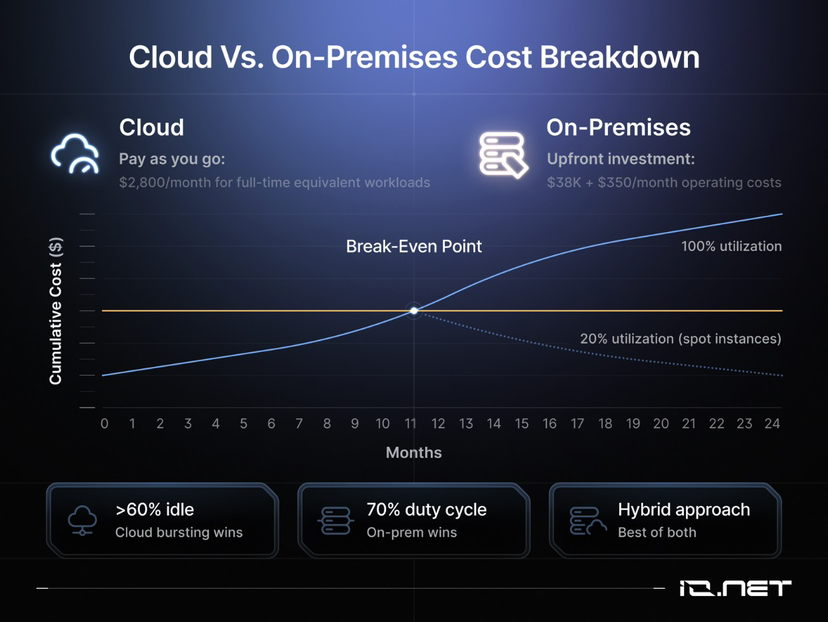
1. Cost data comparison
• On-prem deployment: The initial investment for a 64-core GPU cluster is approximately $38,000, with an additional annual power cost of around $4,200.
• Cloud leasing: The cost for equivalent cloud resources is approximately $2,800 per month.
2. Break-even analysis and usage scenario evaluation
The break-even point for on-premises deployment is 14 months, but this only holds true if the equipment runs 24/7. If workload runtime is only 20%, using cloud spot instances offers better capital expenditure (Capex) efficiency.
3. Resource orchestration and flexibility
Resource orchestration (Orchestration) is key to achieving architectural flexibility. Refer to common architectures used by fintech companies: use tools like Slurm-on-Kubernetes to keep sensitive models running locally, while bursting to 10,000+ cloud cores during high-demand scenarios (e.g., overnight testing).
4. Procurement decision threshold
Decisions should be based on core-hours:
• Purchase hardware: Task load exceeds 1,200 core-hours/month.
• Lease cloud: Task load is below this value.
5. Utilization monitoring and resource adjustment
Actual GPU utilization data should be recorded, rather than relying on guesswork:
• If idle time > 60%: Indicates hardware resource waste; consider shifting to cloud bursting mode.
• If load rate (Duty Cycle) consistently > 70%: Recommend purchasing hardware or leasing bare metal servers (Bare Metal).
6. Large-scale parallel processing strategy
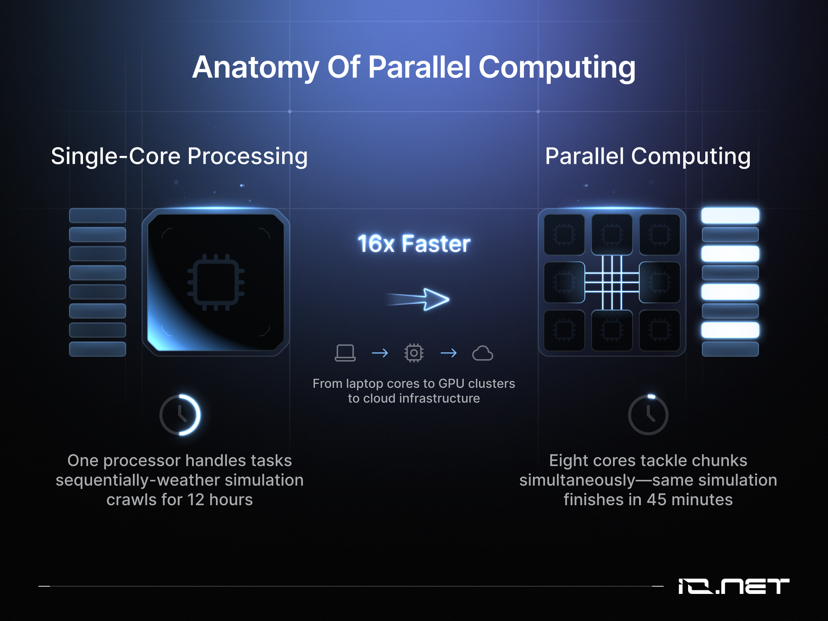
For large-scale workloads, a hybrid strategy is recommended: keep baseline compute on-premises and use decentralized cloud resources to handle peak demand. Continuously monitor usage data and dynamically adjust resource scale accordingly.


