
Everyone assumes blob identifiers are simple: hash the data, use that as the ID. Walrus proves that's thinking too small. A blob's true identity includes both the data hash and the encoding metadata. This single design choice enables verification, deduplication, versioning, and Byzantine safety—all simultaneously.
The Hash-Only Identity Problem
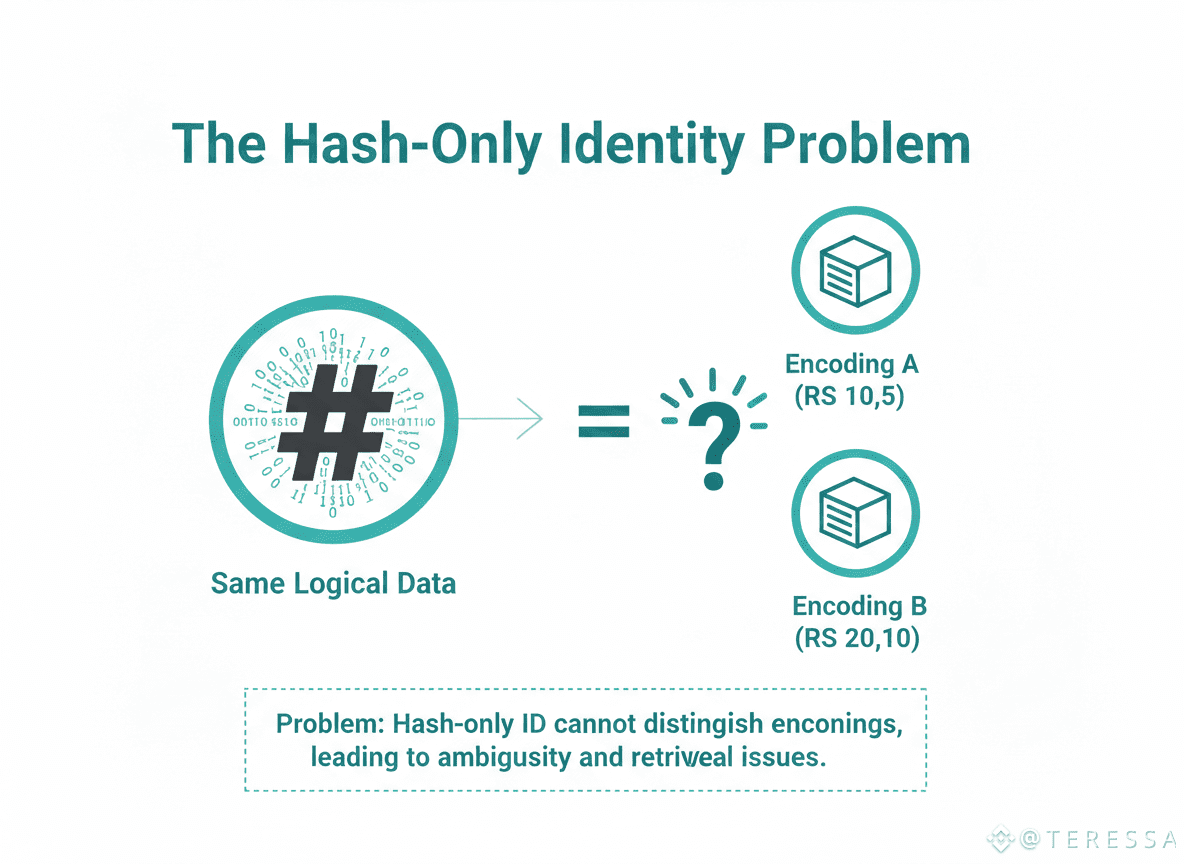
Traditional blob storage uses content-addressed identifiers: hash the data, that's your ID. Simple, elegant, obvious.
Here's what breaks: encoding changes. A blob stored with Reed-Solomon (10,5) has a different encoding than the same data stored with Reed-Solomon (20,10). They're the same logical data but require different retrieval processes.
Using hash-only IDs, these are identical. Validators retrieve the blob and have no way to know which encoding they should reconstruct. Clients requesting the blob don't know which encoding to expect.
This forces expensive choices: store multiple encodings of the same data (wasteful), or have clients know the encoding out-of-band (fragile and error-prone).
Walrus's Blob ID magic is better.
Hash Commitment + Metadata = Unique Identity
Walrus Blob IDs are more sophisticated: they combine the content hash with encoding metadata. The ID uniquely identifies not just the data, but the exact encoding scheme and parameters.
Here's what this buys you:
First, Byzantine safety. The Blob ID proves validators are storing the exact encoding committed to. A validator claiming to store a blob with ID X must serve data that re-encodes to produce ID X. They can't claim they're storing the data with a different encoding.
Second, deduplication. If the same data is stored with multiple encodings, the multiple IDs make that visible. You can deduplicate the underlying data while maintaining distinct Blob IDs for different encoding schemes.
Third, verification simplicity. When you retrieve a blob, the ID tells you exactly what encoding to expect. You don't need to negotiate with validators or verify separately. The ID itself is the verification anchor.
Fourth, versioning. If you re-encode a blob to a different scheme, it gets a new ID. The history of encodings is visible and traceable.
How This Works Architecturally
The Blob ID is computed as: Hash(data || encoding_scheme || encoding_params)
This produces a unique identifier that captures:
What data is stored (via the hash)
How it's encoded (Reed-Solomon with specific parameters)
How many shards (k and n values)
Committee assignments and epoch information
Every piece of information that affects retrieval and verification is part of the ID.
When you request blob with ID X, the network knows:
Exactly what data you want
Exactly how it's encoded
Exactly which validators should have shards
Exactly how to verify it
No ambiguity. No negotiation.
Byzantine Safety Through Identity
Here's where design elegance shows: the Blob ID itself is cryptographic proof of Byzantine safety.
A validator claiming to store blob with ID X is implicitly committing to:
Having data that hashes to the content hash in X
Using the exact encoding scheme specified in X
Maintaining the exact shard parameters in X
If they deviate—different encoding, different parameters, corrupted data—the ID verification fails. They're caught.
The ID is the Byzantine safety mechanism. It's not a signature from validators. It's not a quorum commitment. It's the mathematical uniqueness of the encoding.
Deduplication Without Ambiguity
Traditionally, deduplication creates problems: if you store data on-chain twice with different encodings, how do validators know which version to serve?
With Blob ID magic, this is clear. Data stored with encoding A has ID X. Data stored with encoding B has ID Y. Even though they're the same underlying bytes, the IDs make them distinct.
Validators can deduplicate the raw data while maintaining separate Blob IDs. The system knows which encoding each ID requires.
This saves storage while maintaining clarity.
Verification Without Extra Rounds
Traditional systems need extra verification rounds: request blob, get data, verify it matches your expectations, confirm the encoding is correct.
Blob ID magic makes this instant. The ID tells you what to expect. The returned data either matches the ID or it doesn't. One check, deterministic result.
This is what makes read verification efficient. The ID is pre-computed. Verification is checking if returned data hashes and encodes to match the ID. Done.
Metadata as Safety Constraint
Encoding metadata isn't just informational. It's a safety constraint that validators can't violate.
Want to use fewer shards to reduce storage? That changes the Blob ID. You're no longer storing the same blob. You're storing a different blob with a different ID.
Want to change encoding schemes? New ID. Different blob.
This creates accountability. You can't silently degrade a blob's safety by using fewer shards. The change is visible through ID change.
Versioning and Evolution
As blobs age, you might want to re-encode them. Maybe committee size changes. Maybe you optimize for different fault tolerance. You create a new Blob ID for the new encoding.
The system maintains both versions. You can track when blobs moved between encodings. You can prove the evolution of each blob's encoding.
This is radical transparency compared to traditional storage where encoding changes are invisible.
Computational Efficiency
Here's the practical win: computing the Blob ID is cheap. Hash the data once, append metadata, hash again. Negligible overhead.
Verification using the ID is also cheap. Compare one hash against the ID. Done.
This is different from systems that require signature verification, quorum checks, or multiple rounds. Blob ID verification is O(1) and nearly free.
Preventing Encoding Attacks
Byzantine validators might try to serve data encoded differently than committed. With traditional identifiers, this is hard to detect.
With Blob IDs, it's impossible. The ID uniquely specifies the encoding. Serving different encoding breaks the ID. The attack is detectable immediately.
Comparison to Content-Addressed Storage
Content-addressed (hash-only):
Simple IDs
Ambiguous when data has multiple encodings
Requires out-of-band encoding information
Vulnerable to encoding attacks
Hard to track encoding evolution
Blob ID magic:
IDs encode metadata
Unambiguous encoding specification
Self-describing blobs
Encoding attacks detected immediately
Evolution is visible and traceable
The difference is categorical.
Real-World Implications
For applications storing blobs:
Deduplication is clear (different encodings have different IDs)
Encoding is self-describing (ID tells you how to retrieve)
Evolution is traceable (new encoding = new ID)
Security is verifiable (ID is Byzantine safety proof)
No more guessing about which encoding is active. No more assuming encoding metadata. No more wondering if validators changed something silently.
The Psychology of Clarity
There's something satisfying about identifiers that are self-describing. The ID tells you everything you need to know about what you're retrieving.
This shifts infrastructure from "trust the validator told you the truth" to "the identifier itself is proof of what you're getting."
Walrus Blob ID magic transforms blob identity from a simple content hash to a comprehensive specification that includes data, encoding, and metadata. This single design choice enables Byzantine safety, deduplication, verification simplicity, and encoding evolution—all simultaneously.
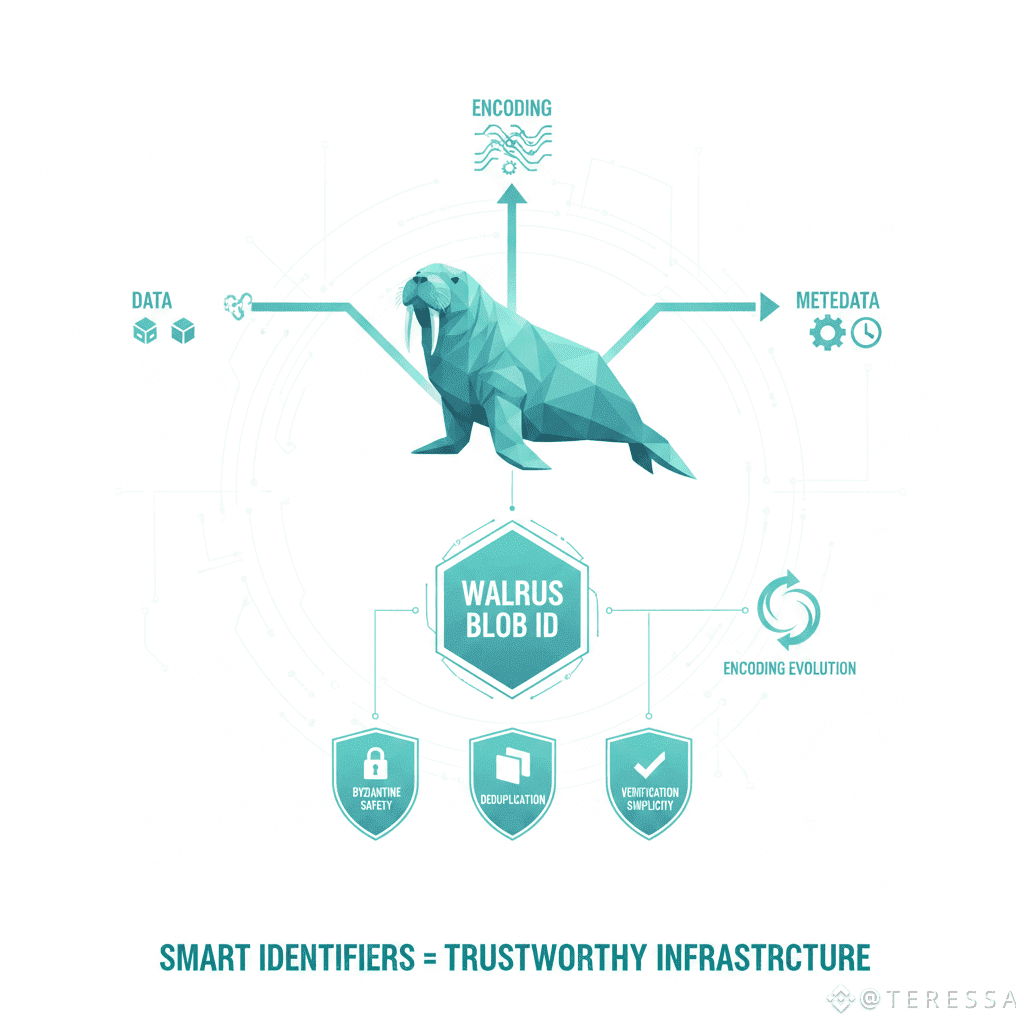
For decentralized storage that needs to be transparent about what it's storing and how it's encoding it, this is foundational. The Blob ID becomes your proof that data is stored correctly, encoded safely, and verified completely. Walrus proves that simple identifiers are too simple. Smart identifiers are what enable infrastructure that's actually trustworthy.

