
When I first looked at Walrus Protocol, I made the same lazy comparison most people do.
Decentralized storage versus cloud storage. New system versus old giant. The usual story. It didn’t hold for more than a few minutes. The deeper I went, the clearer it became that Walrus isn’t really arguing with AWS or Google Cloud at all. It’s arguing with a belief most infrastructure quietly depends on: that failure is rare, manageable, and mostly someone else’s problem.
Cloud storage works because it assumes a controlled world. Data centers are stable. Networks are predictable. Operators responds very quickly. When something breaks, it breaks in a known way, with contracts and playbooks ready. That assumption has held long enough that it feels natural. But it starts to fray the moment you leave that controlled environment. Web3 doesn’t just introduce new users or new apps. It introduces chaos as a baseline condition.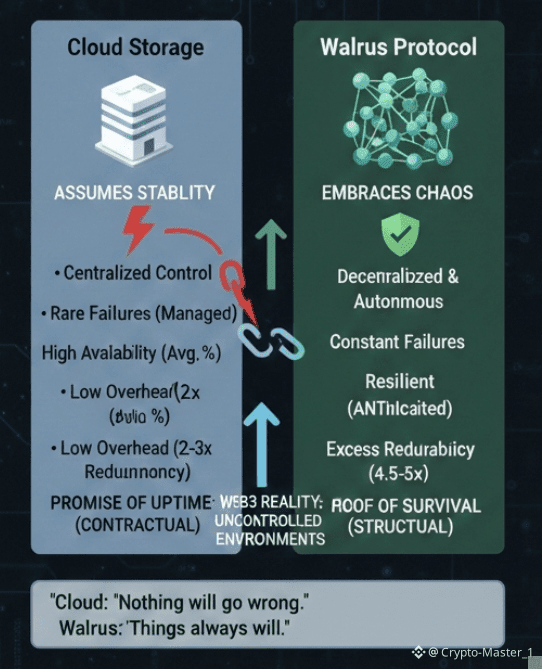
What struck me is that Walrus starts from the opposite place. It assumes things will fail. Nodes will disappear. Disks will corrupt. Networks will partition. Operators will vanish without notice. The system isn’t embarrassed by this. It builds around it.
On the surface, Walrus looks like a decentralized storage network with erasure coding and redundancy. That description is technically accurate and emotionally empty. Underneath, it’s a bet that storage should behave more like a living system than a warehouse. Data isn’t just placed somewhere and hoped for. It’s continuously verified, repaired, and re-encoded as conditions change.
Take redundancy. Walrus targets roughly 4.5 to 5 times redundancy for stored data. That number sounds high until you understand what it replaces. Traditional decentralized storage often chases minimal overhead, sometimes closer to 2x, to look efficient on paper. That works until nodes leave faster than repairs can happen.
Walrus chooses excess deliberately, not to look impressive, but to buy time. Time to detect failures. Time to heal. Time to avoid cascading loss.
Detection matters more than peoples think. Walrus nodes regularly verify stored fragments instead of assuming silence means success. That constant checking creates load, but it also creates awareness. When something degrades, the system knows early. Early knowledge is the difference between quiet repair and visible catastrophe.
That design choice leads to another effect. Repair traffic becomes predictable. Instead of repair storms triggered by sudden mass failure, Walrus spreads the work out. It’s less exciting, more steady. Predictability is underrated until you try to build serious applications on top of storage. AI systems, archival data, and long-lived onchain state don’t tolerate surprises well.
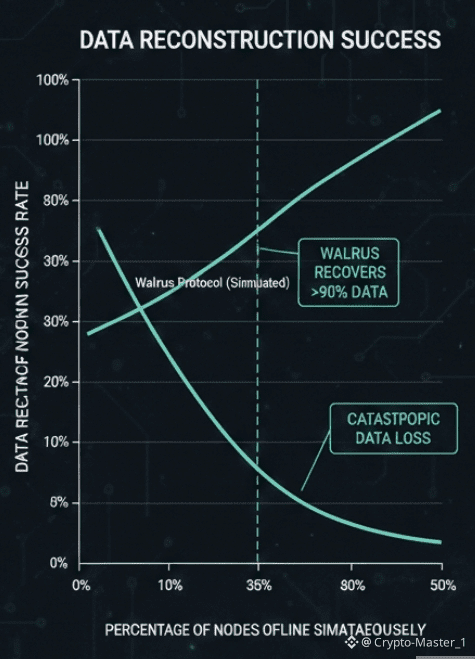
There’s real data backing this philosophy. In testing and early deployments, Walrus has demonstrated the ability to recover full data sets even when a large portion of nodes go offline simultaneously. In some simulations, over one third of storage providers disappeared, and the system still reconstructed data without user intervention. That number matters because real networks don’t lose nodes one at a time. They lose them in clusters. Regions go dark. Operators rage quit.
Meanwhile, cloud providers report availability in percentages like 99.9 or 99.99. Those numbers hide the truth in averages. They say nothing about correlated failure. They also rely on centralized control to restore service. Walrus doesn’t get that luxury. No one is on call. No one can force nodes to behave. The system has to fix itself.
That self-repair comes with costs. Storage is more expensive per byte than hyperscale cloud. Write latency is slower than centralized systems. There’s overhead in verification and coordination. Walrus doesn’t deny this. It accepts it. The tradeoff is that reliability is earned structurally rather than promised contractually.
What makes this more than a storage discussion is how it lines up with what’s happening right now. AI workloads are shifting from short-lived queries to long-running agents. These agents accumulate memory over months, not minutes.
Losing data isn’t just inconvenient. It breaks continuity. At the same time, regulators are pushing for auditable systems where data integrity can be proven, not assumed. Quietly, the bar for storage is moving upward.
Walrus sits in that gap. It doesn’t optimize for headline throughput. It optimizes for the boring parts that decide whether systems survive five years instead of five weeks. Underneath the branding, it’s really a reliability instrument masquerading as storage.
There are risks here. The economic model depends on sustained demand for high-durability storage, not just speculative interest. If users only care about cheap space, Walrus loses its edge. The protocol also depends on enough honest participation to maintain redundancy targets. If incentives drift or operators chase short-term yield, the system could thin out. Early signs suggest the designers are aware of this, but awareness isn’t a guarantee.
Still, something interesting is happening. Builders are starting to design applications where storage assumptions are explicit. They ask not just where data lives, but how it survives stress. That shift is subtle, but it changes what infrastructure gets chosen. Quiet systems start to matter more than flashy ones.
If this holds, Walrus isn’t winning because it’s decentralized. It’s winning because it treats failure as normal and plans accordingly. That mindset feels increasingly aligned with the direction of the space. Less faith. More structure. Less promise. More proof.
The sharp observation that sticks with me is this: cloud storage sells the comfort that nothing will go wrong, while Walrus is betting that things always will, and building something steady enough to outlast that truth.

