A few months back, I was messing around with a small AI agent experiment on a side chain, trying to feed it live datasets pulled from on-chain sources. Nothing exotic. Just tokenized market data, some historical trade blobs, a few image sets to test how the model reacted to volatility changes. That’s when storage became the bottleneck. The data sizes weren’t crazy by Web2 standards, but in crypto terms they were huge. Fees stacked up fast on most decentralized storage options, retrieval slowed down during busy hours, and there was always that lingering worry that if enough nodes dropped, some chunk of data would just disappear. After years of trading infra tokens and building small dApps, it was frustrating that something as basic as reliable data storage still felt fragile enough to push me back toward centralized clouds.
The core problem hasn’t really changed. Most blockchain storage systems were designed around small pieces of transactional data, not the kind of heavy datasets AI workflows actually need. To compensate, they lean on brute-force redundancy. Data gets replicated again and again to keep it available, which drives costs up without guaranteeing speed. Developers end up paying for safety they may not even get, while users deal with slow reads when networks get busy, or worse, data gaps when availability assumptions break. For AI-heavy applications, that friction becomes a deal-breaker. Models need verifiable inputs, agents need fast access, and datasets need to be programmable, not just archived. Without infrastructure built for that reality, everything stays half on-chain and half off, which defeats the point.
This works because it reminds me of the difference between shared warehouses and isolated storage silos. Warehouses scale because they’re optimized for volume, not duplication. The behavior is predictable. Goods are spread efficiently, tracked carefully, and accessible when needed. Silos keep everything isolated and duplicated, which feels safer, but it’s slow and expensive. The warehouse only works if the structure is solid, but when it is, it beats brute-force redundancy every time.
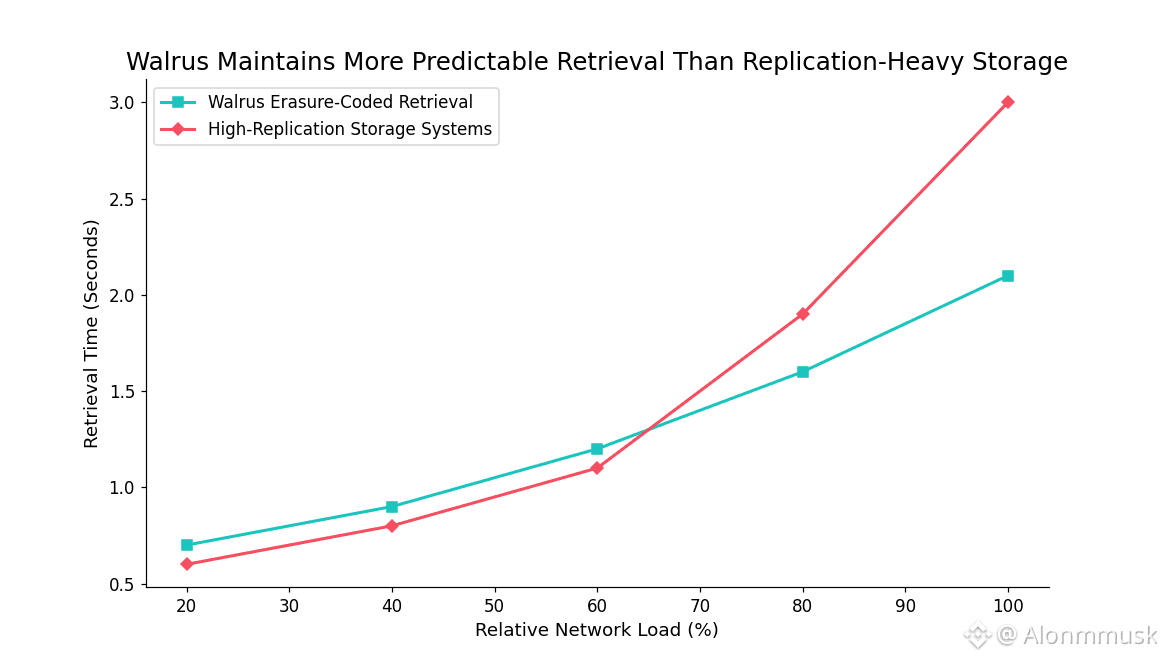
That’s where @Walrus 🦭/acc starts to make sense. It’s built as a storage layer on top of Sui, specifically to handle large blobs like datasets, media, and model files without the usual bloat. Instead of blanket replication, data is encoded, split, and spread across nodes with a relatively low redundancy factor. The idea isn’t to make storage bulletproof through excess, but resilient through structure. That design choice matters for AI use cases where agents might need to pull images, weights, or training data on demand without running into unpredictable fees or lag. Walrus intentionally avoids trying to be a universal file system. It doesn’t chase granular permissions or heavyweight encryption layers. The focus stays narrow: make large data verifiable, affordable, and accessible inside smart contract logic so information itself can be treated as an asset.
One of the more practical design choices is erasure coding. Data is broken into fragments with parity added, so even if a portion of nodes go offline, the original file can still be reconstructed. That resilience comes with much lower overhead than full replication, and in practice it scales cleanly as node counts grow. Another key piece is how deeply #Walrus integrates with Sui’s object model. Blobs aren’t bolted on as external references. From a systems perspective, they’re treated as first-class objects, which means metadata, proofs, and access logic can be handled directly on-chain. From a systems perspective, for AI workflows, that cuts out layers of glue code and reduces latency when agents query or validate data. The behavior is predictable.
Recent releases push this direction further. The RFP program launched recently to fund ecosystem tools has drawn a noticeable number of AI-focused proposals, from dataset registries to agent tooling. The Talus integration in early January 2026 is a good example of where this is heading. AI agents built on Sui can now store, retrieve, and reason over data directly through Walrus, with verifiable guarantees baked in. Model weights, training sets, even intermediate outputs can live on-chain without blowing up costs, which is a meaningful step beyond “storage as an archive.”
The $WAL token itself stays in the background. It’s used to pay for storage in a way that’s anchored to stable pricing, so users aren’t guessing what their costs will be week to week. You lock WAL based on how much data you store and for how long. Node operators stake it to participate, earning a share of fees and emissions, but facing penalties if availability checks fail. Structurally, governance uses WAL for tuning parameters like redundancy levels or onboarding rules, keeping incentives aligned without layering on unnecessary complexity. The behavior is predictable. Structurally, emissions taper over time, nudging the system toward sustainability rather than speculation.
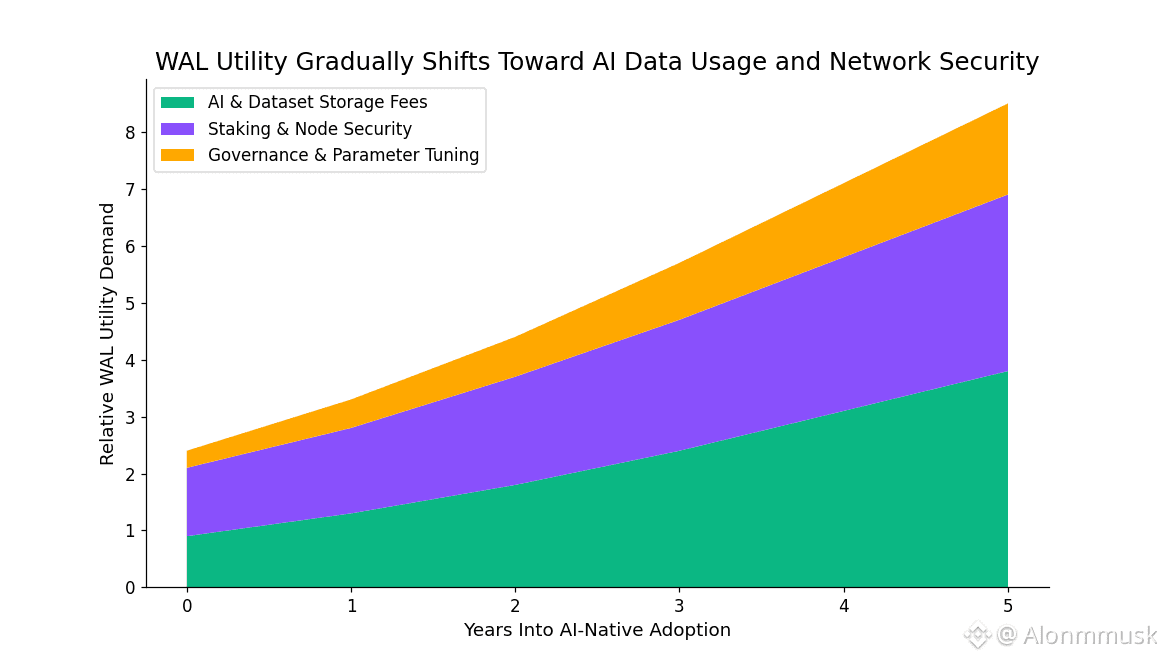
From a market perspective, WAL sits around a $280 million valuation, with daily volume closer to $10 million. It trades enough to stay liquid, but it’s not whipsawing on memes. Network stats paint a clearer picture of intent. Devnet reports show hundreds of active nodes, and pilot deployments are already operating at petabyte-scale capacity, which is the kind of metric that actually matters for AI use cases.
Short term, price action tends to follow headlines. The $140 million raise led by a16z and Standard Crypto in December 2025 pulled attention quickly, but like most infrastructure stories, the excitement faded once the announcement cycle moved on. I’ve seen $WAL move sharply on partnership news, then drift as the broader AI narrative cooled. That’s normal. Long-term value here isn’t about one announcement. It’s about whether developers quietly keep building and whether agents keep coming back to store and query data because it just works. Once a system becomes part of a workflow, switching away gets expensive.
The risks are real. Storage is a crowded field. Filecoin has sheer scale, Arweave owns the permanence narrative, and cheaper IPFS-style systems exist even if they’re weaker on guarantees. Walrus also inherits Sui’s learning curve. Move isn’t Solidity, and that alone slows adoption for some teams. A more structural risk would be correlated node failures. If enough staked nodes went offline during a surge in demand, reconstruction thresholds could be tested, leading to temporary unavailability. Even short outages can damage confidence when AI systems depend on real-time data.
Stepping back, though, infrastructure like this doesn’t prove itself through hype. It proves itself through repetition. The second dataset upload. The tenth retrieval. The moment builders stop thinking about storage at all. If Walrus reaches that point for AI-native applications, it won’t need loud narratives. It’ll already be embedded where the data lives.
@Walrus 🦭/acc #Walrus $WAL


