我先抛个你一定经历过的真实场景:同一份研究,你白天用 GPT 打草稿,晚上切到 Claude 做结构,第二天再用 Gemini 找资料——结果每换一次平台,你就要把“我是谁、我在写什么、我已经推到哪一步、我不想要什么风格”重新解释一遍。你以为你在使用 AI,其实你在给 AI 交“上下文税”。这就是我说的:AI 时代最贵的不是算力,而是记忆的断裂。
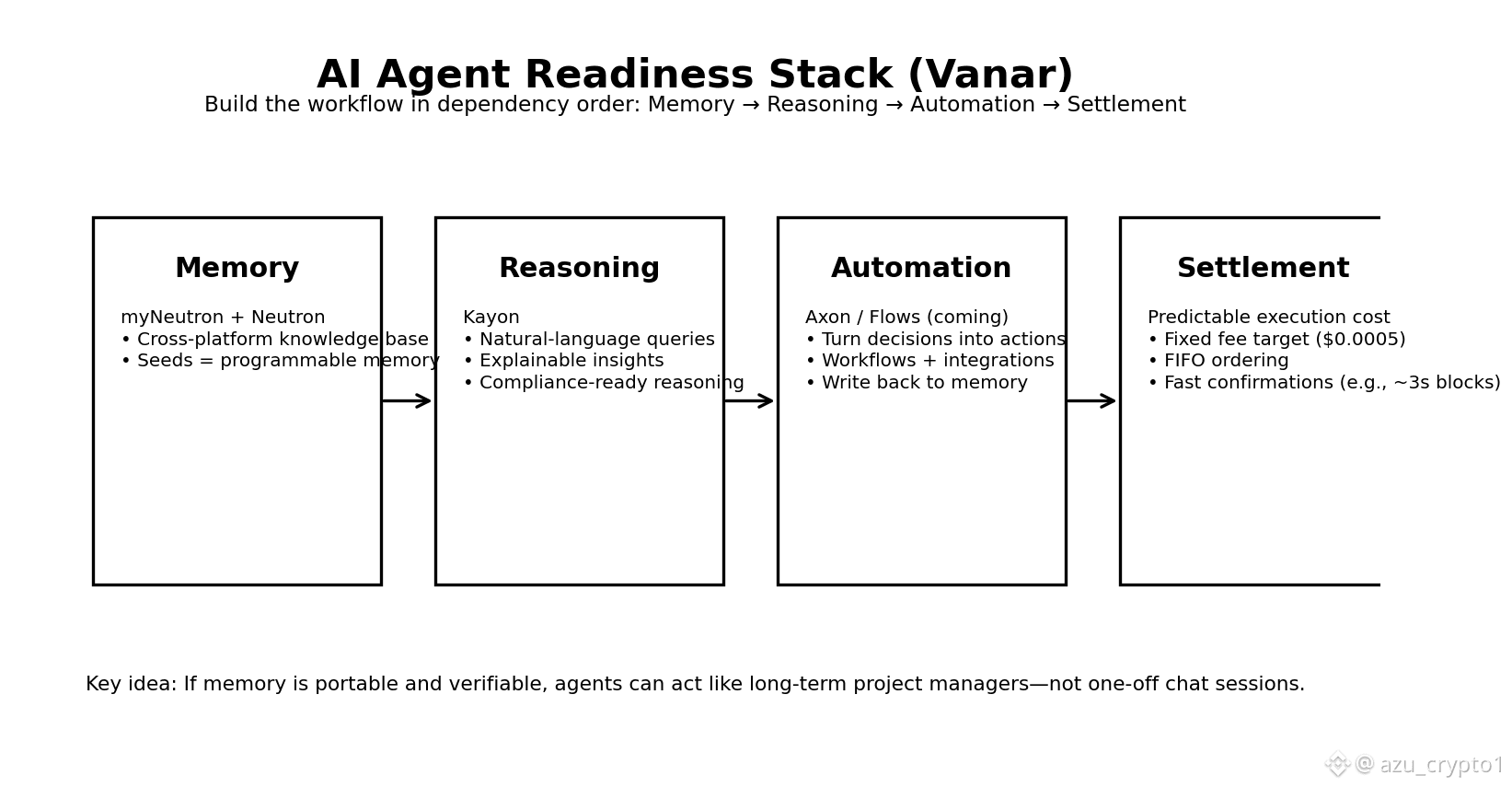
所以我越来越不吃“AI 就绪”这种口号,我只把它当工程问题来审:一个智能体要完成任务,至少要满足四件事——带着上下文走(记忆)、能解释它为什么这么做(推理)、能把判断变成可执行动作(自动化)、还能用可预测成本把结果结算(结算)。TPS 当然重要,但它早就不该是第一指标;对智能体来说,“能稳定跑闭环”比“能跑分”值钱得多。
Vanar 在今天这条线上,给的不是一句“我们也做 AI”,而是把“记忆层”先端出来让你摸得到。它用 myNeutron 把问题说得非常直白:你需要一个跨平台的通用知识库,让记忆不被某一家模型或某一个聊天窗口锁死,切换 ChatGPT、Claude、Gemini 这类平台时,知识库还是同一个,能被持续注入上下文。 这一步看似“产品”,本质是基础设施——因为只有当记忆能跨平台携带,智能体才可能变成“长期项目经理”,而不是“单次会话的临时工”。
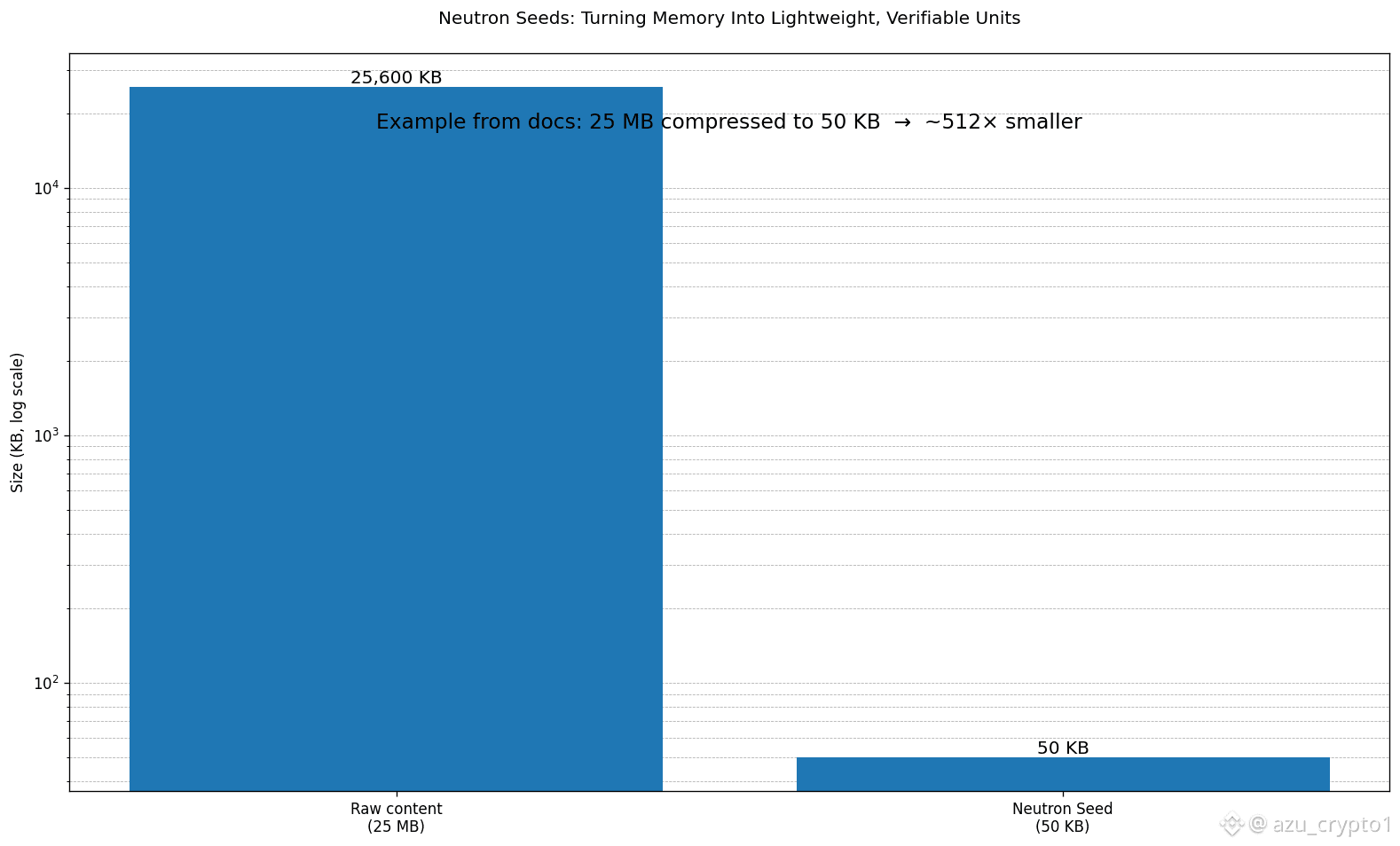
但 myNeutron 的意义还不止“把资料集中起来”。真正硬核的是它背后那层 Neutron:Vanar 把 Neutron 写成一种“AI 原生内存层”,核心动作不是存文件,而是把数据重构成可编程的 Seeds。官方页面直接给了一个非常能打的数字:25MB 压到 50KB,用语义、启发式与算法层的压缩,把原始内容变成超轻量、可加密验证的 Neutron Seeds。 这个数字在文章里特别好用,因为它把“记忆层不是口号”讲成了一次可感知的工程成果:不是挂一个 IPFS 链接,而是把内容变成能被检索、能被引用、能被智能体消费的语义单元。
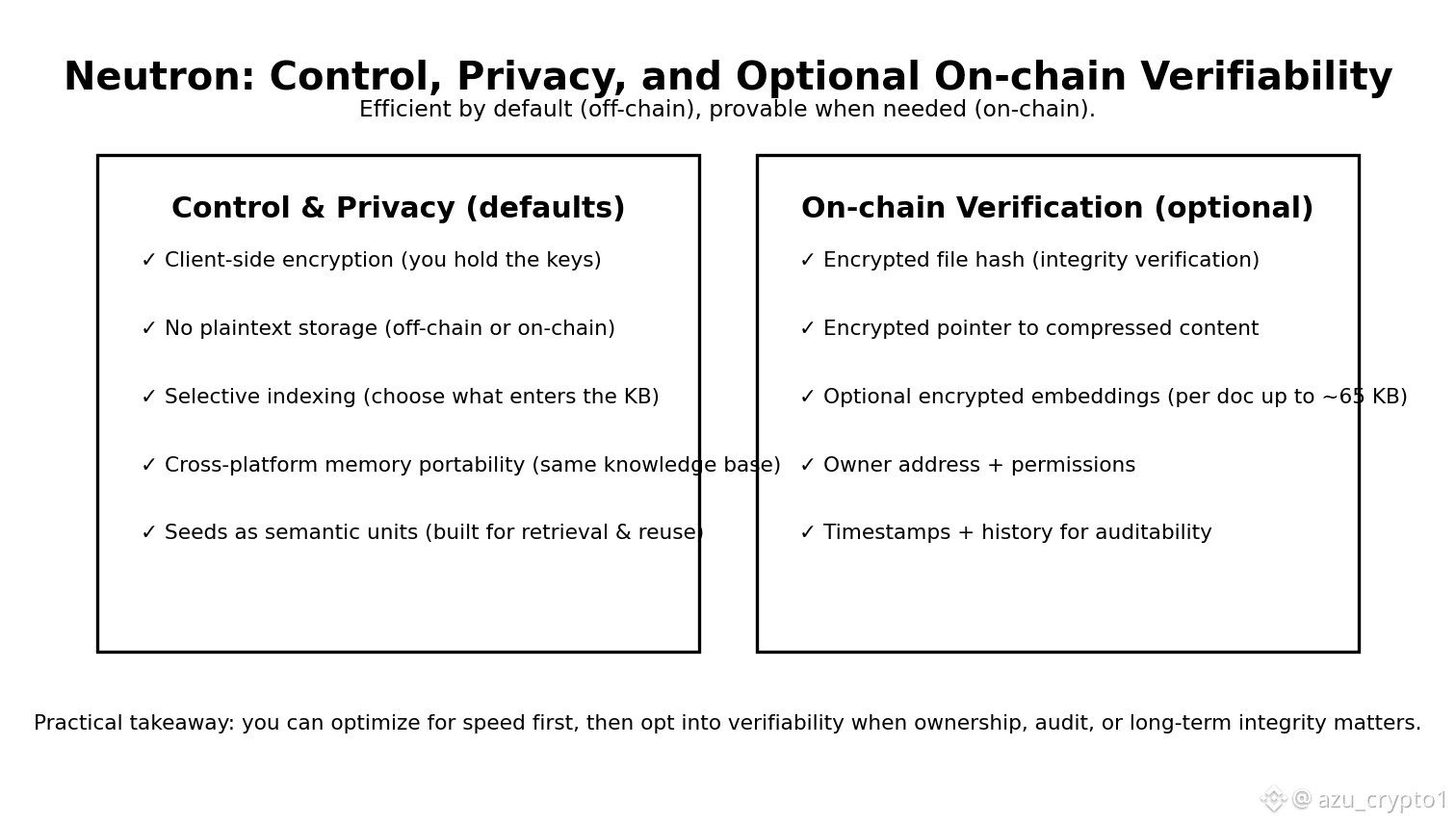
接着你要问:Seeds 到底是什么?别急,Vanar 的文档把 Seeds 的定义写得很“工程师”:Seed 是 Neutron 的基本积木,一个 Seed 可以代表文档、邮件、图片、结构化段落、视觉参考与描述,甚至可以包含跨 Seed 的链接关系;而存储方式走的是混合架构——默认 offchain(快、灵活),但你可以选择把它做成 onchain 记录来获得验证、所有权、长期完整性和审计性。 这点很关键:它把“效率”和“可信”拆开给你选,而不是强迫你在性能和安全之间二选一。
再往下看,技术可信度来自细节。文档里解释了当 Seed 选择上链时,Neutron 使用专门的文档存储合约,合约里会包含:加密后的文件哈希用于完整性验证、指向压缩文件的加密指针、并且还能把 embeddings 以加密方式存到链上(每份文档最高 65KB),同时记录 owner 地址、权限设置、时间戳与历史。 你看,这就把“可验证”落到了具体字段:验证靠哈希,权限靠地址,追溯靠时间戳和历史,而不是靠一句“我们很安全”。
更现实的问题是企业会担心:数据一旦进了 AI,是不是就“出不来”了?Vanar 在 Neutron 的隐私与所有权文档里给了明确答案:Client-side encryption(端侧加密),敏感数据在你的设备上就先加密;No plaintext storage(无明文存储),不管 offchain 还是 onchain,都不读不存未加密内容;还有 Selective indexing(选择性索引),你自己决定哪些文件/消息/文件夹进入知识库。 这其实是在对齐企业最在乎的那条底线:所有权不只是“我能导出”,而是“我掌握密钥,我决定上链与否,我决定可索引范围”。
好了,记忆层有了,那“推理”怎么落地?Vanar 把 Kayon 放在第三层,定位为 AI reasoning layer:提供自然语言的区块链查询、上下文洞察与合规自动化,核心意思是把 Seeds 这种“可用记忆”变成“可解释判断”。 我喜欢用一句话概括 Kayon:它不是替你写答案,它是替你把记忆组织成可行动的推理链——你问的不再是“给我总结一下”,而是“基于我这批 Seeds,给出可执行的下一步,并解释为什么”。
自动化层(Axon)与行业应用层(Flows)目前在官网上标注 coming soon,但这个顺序本身就透露了 Vanar 的思路:先把记忆做成“可携带、可验证、可控隐私”的基础设施,再把推理做成可解释接口,最后才让自动化把推理落到链上动作。 这就是我说的“AI 就绪不是模型上链”,而是把智能体跑工作流所需的组件按依赖关系装配起来——先内存,再大脑,再手脚。
结算。智能体一旦开始跑工作流,它不是一天发几笔交易,它是高频地“检索—判断—执行—写回记忆”。这时候最怕的不是手续费高,而是手续费像过山车。Vanar 的白皮书在这一点上写得非常直:它的基础承诺之一是把交易费做到固定且可预测,并且把低费用锚定到美元价值,目标是把每笔交易压到 $0.0005 这个量级,同时强调即使 gas token 价格出现 10x/100x 变化,用户仍应支付接近该水平的费用。 交易排序也明确采用 fixed fee + FIFO/先来先服务,验证者按 mempool 接收顺序打包,避免“竞价抢跑”把自动化系统搞成不稳定的拍卖市场。 更进一步,白皮书还写了 3 秒出块与每块 30 million gas limit 的启动设定,为的就是让系统更适合高频交互与快速确认。
所以你现在能把今天的逻辑串起来了:myNeutron 解决“跨平台上下文丢失”;Neutron 把数据压成 Seeds,让记忆变成可编程、可验证的语义单元;文档用混合存储与上链合约细节补上可信度;隐私与所有权用端侧加密、无明文存储、选择性索引给企业吃下定心丸;Kayon 把记忆变成推理接口;最后结算层用固定费与 FIFO 给智能体一个能预算、能长期跑的成本底盘。
站在 Web3 爱好者角度,这套叙事最性感的地方是:它把“链上数据”从死链接变成活资产;站在加密投资者角度,更重要的是你终于有一套能跟踪的“AI 就绪指标”了——不是看它说了多少 AI,而是看 myNeutron 的真实使用留存、Seeds 的增长与结构化程度、选择上链验证的比例、以及推理层(Kayon)是否形成高频、可复用的查询与自动化调用。因为只有当“记忆×推理×自动化×结算”变成真实流量,$VANRY 才可能从叙事资产变成基础设施行为的定价锚。
你现在用 AI 最大的痛点到底是哪一个——“每次都要重讲上下文”、还是“它给的答案没法解释”、还是“不能自动落地执行”、还是“链上结算成本不可预测”?你在评论区选一个,我直接沿着你的答案把“跨链与规模化”写成一条可执行的路线。
